

Spis Treści
Hyper Historian: Analiza danych historycznych
Performance Caltulation to wbudowane funkcje w Hyper Historian umożliwiające analizę danych historycznych, aby uzyskać użyteczne informacje.
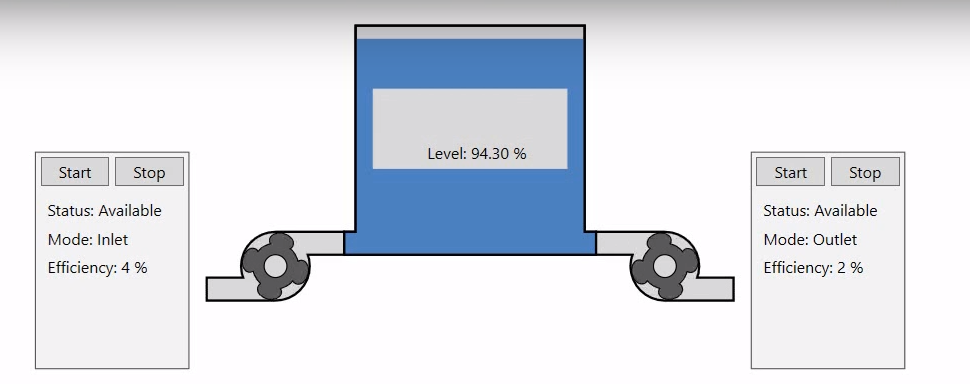
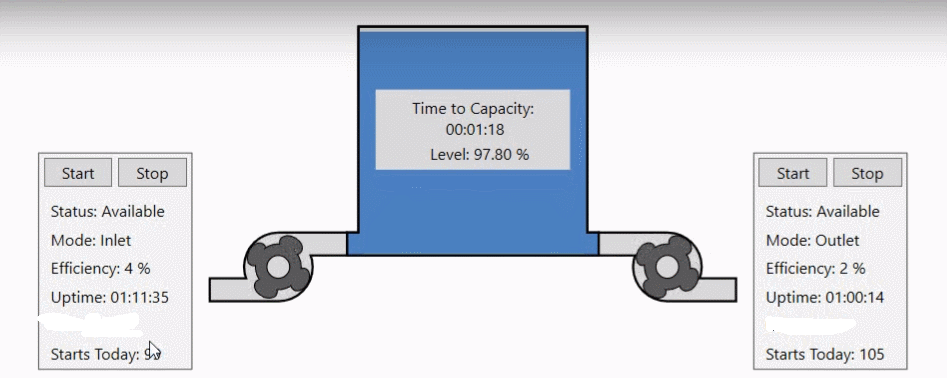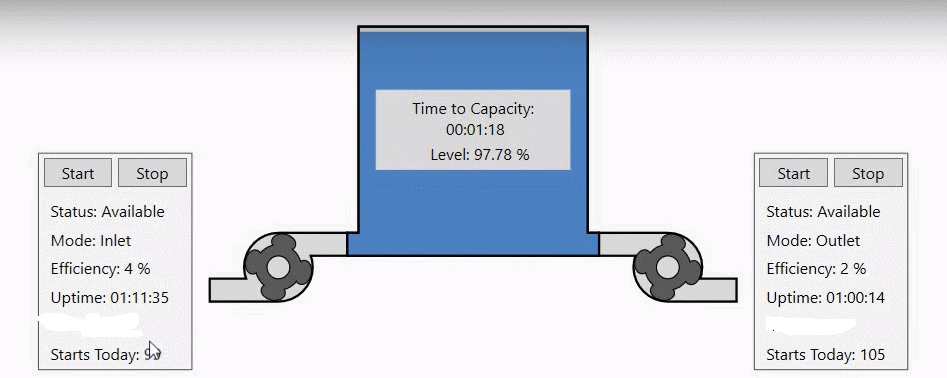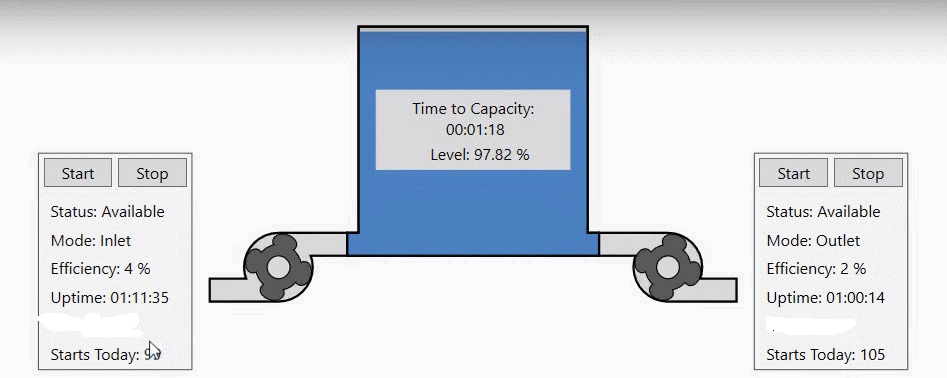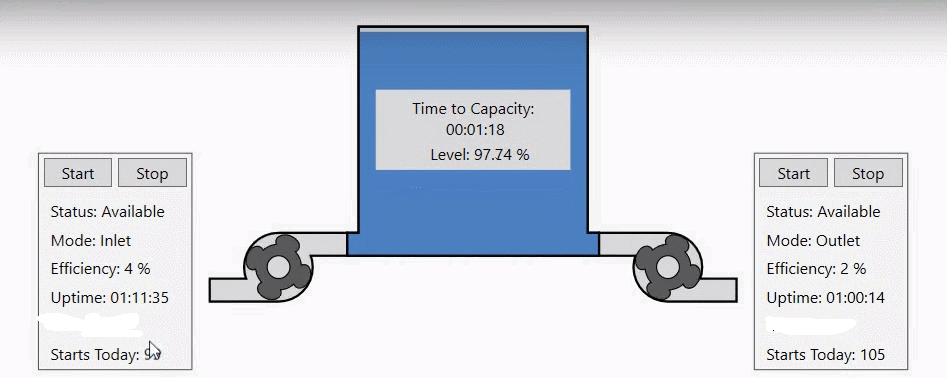
Przeanalizujmy następującą sytuację: posiadamy zbiornik oraz dwie pompy, jedną odpowiedzialną za napełnianie zbiornika, a drugą za opróżnianie. Zbieramy i archiwizujemy dane dotyczące efektywności, statusu pomp i trybu ich pracy oraz poziomu cieczy w zbiorniku.
|
Jednak obecna wizualizacja przedstawia tylko aktualne dane na ten temat. W tym wpisie przedstawię jak wykorzystać dane historyczne do uzyskania użytecznych informacji. Dane historyczne wykorzystam do uzyskania danych o czasie pracy pomp i ilości załączeń oraz przewidywania czasu do napełnienia zbiornika. |
 |
Czas pracy pomp
Konfigurację zaczynamy od stworzenia Tagu kalkulacyjnego w Hyper Historian, następnie zmieniamy typ zmiennej (2), oraz dodajemy calculation trigger (3). Można wykorzystać jeden z skonfigurowanych, lub stworzyć własny.
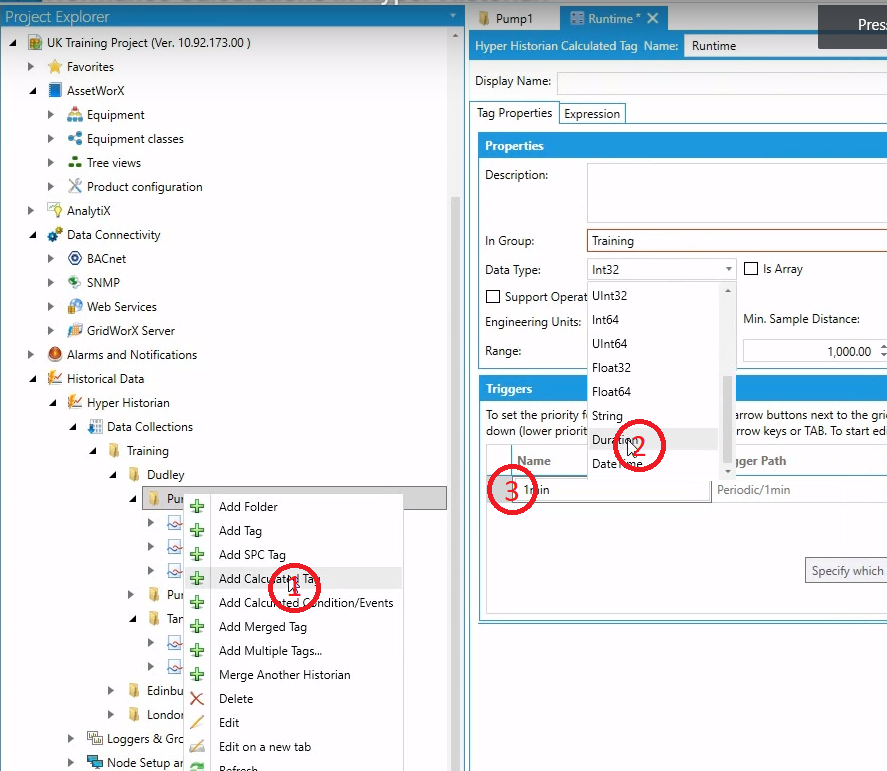
Następnie przejdź do zakładki Expression (1), wybieramy z listy funkcji (2) Functions> History Functions> tagtimestate1(3). Następnie dostosowujemy wyrażenie (zaznaczone czerwonym prostokątem).
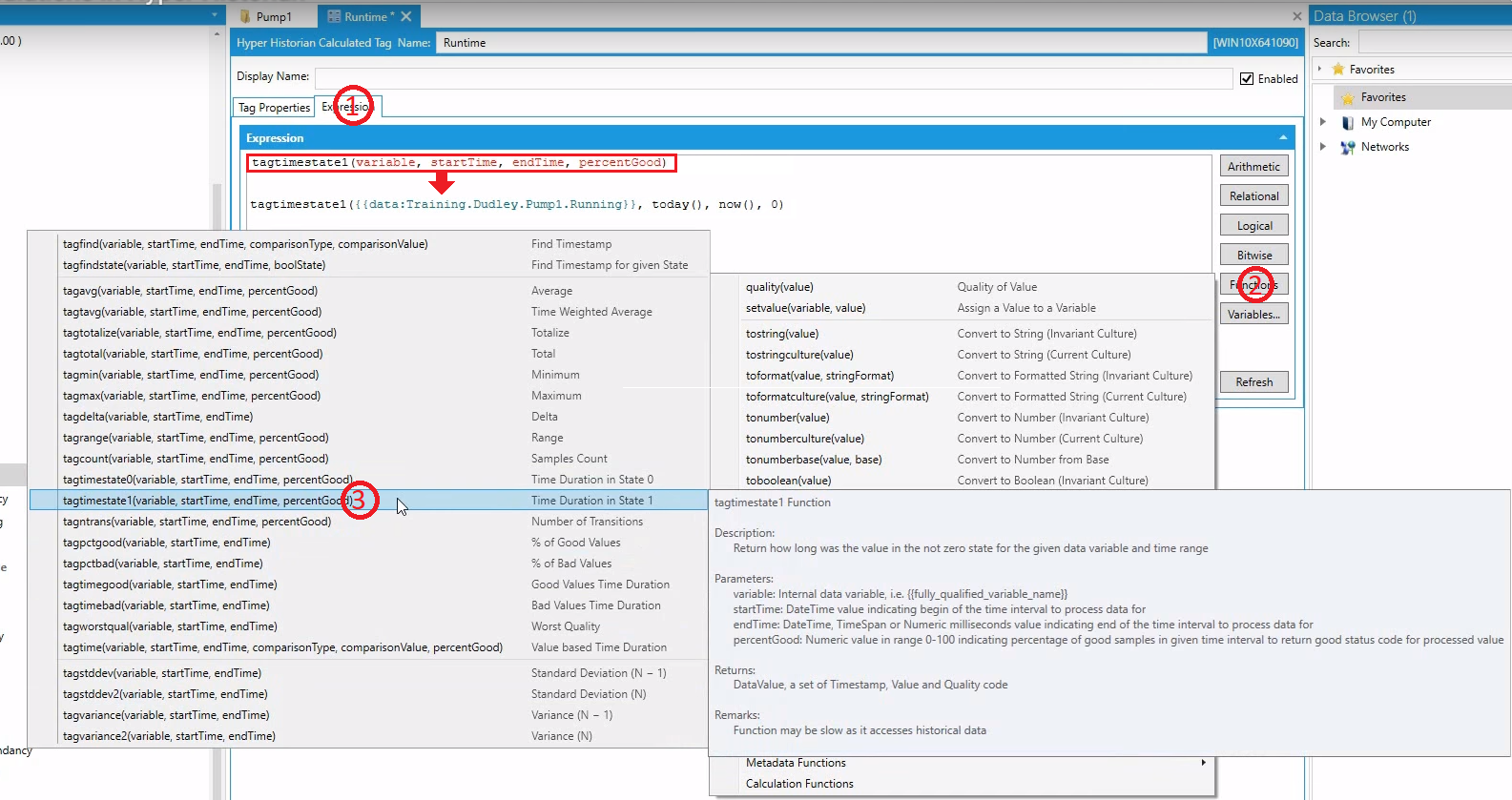
Tak skonfigurowaną zmienna kalkulacyjną wystarczy dodać do ekranu wizualizacji, aby uzyskać informacje o czasie pracy urządzenia (w moim przypadku w ciagu bieżącego dnia).
Ilość załączeń pompy
| Konfiguracja zmiennej obliczającej ilość załączeń pompy w danym zakresie czasu wygląda niemal identycznie jak w przypadku konfiguracji czasu pracy pomp. Jedyną różnicą jest użycie innej funkcji i zmiennej przechowującej informacje o tym czy pompa pracuje. Do zliczania ilości załączeń służy funkcja tagtrans znajdujaca się w Functions> History Functions. | 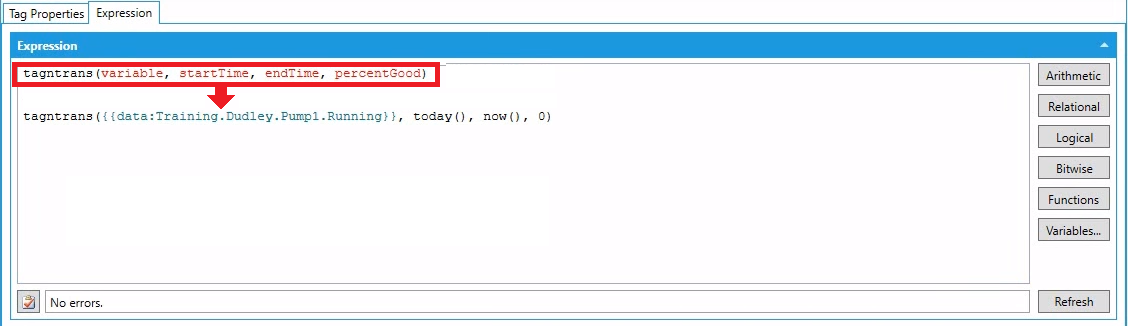 |
Przewidywany czas do napełnienia zbiornika
| Dodanie elementu predykcji wymaga stworzenia bardziej skomplikowanej formuły obliczeniowej, zmiennej kalkulacyjnej. Trzonem funkcji jest funkcja warunkowa IF THEN ELSE oraz wyznaczanie delty pomiaru między kolejnymi obliczeniami. Jeżeli delta jest większa od 0 to znaczy że zbiornik się napełnia i możemy wyznaczyć czas do napełnienia. |  |
tagdelta(/*variable, startTime, endTime*/) - oblicza deltę pomiaru w danym zakresie czasu. trgnamecur() - zwraca wartość czasu aktywnego calculation trigger. tagprevgood(/*variable, dateTime*/) - zwraca wartość poprzedniej próbki pomiaru, którego jakość jest określona jako "dobra".
Podsumowanie
|
Dzięki wbudowanym funkcjom do analizy danych historycznych w Hyper Historian możemy wzbogacić naszą wizualizację o użyteczne informacje. |
 |
Archiwizacja w systemie SCADA zintegrowana z SQL Server
Funkcjonalność modułu archiwizacji od ICONICS
Hyper Historian to wydajne narzędzie pozwalające zbierać duże ilości danych produkcyjnych, nawet do 100 000 próbek na sekundę. Moduł ten wykorzystuje najnowsze standardy, takie jak: OPC UA, OPC DA, OPC XML DA, BACnet, czy SNMP.
Pomimo, że zapisywanie wartości historycznych do plików binarnych (z natywnym rozszerzeniem .hhd) jest wydajnym rozwiązaniem, czasem zachodzi potrzeba odtworzenia składowanych informacji w tabelach - na przykład SQL. W związku z istniejącymi wymaganiami klientów, narzędzie Hyper Historian zostało wyposażone we własny silnik obsługujący zapytania SQL. Komponenty, które składają się na w/w silnik (SQL Query Engine) to:
Podsumowując, z wykorzystaniem tych narzędzi użytkownik jest w stanie wykonywać większość standardowych zapytań SQL na serwerze HDA jakim jest Hyper Historian. |
 |
Dane archiwalne z systemu SCADA w SQL Server - Linked Server
Jak było to już wspominane w innych wpisach, konfiguracje wszystkich modułów systemu SCADA ICONICS są przechowywane w bazach SQL. Co więcej, wiele z tych modułów archiwizuje tam również informacje na temat obsługiwanych procesów.
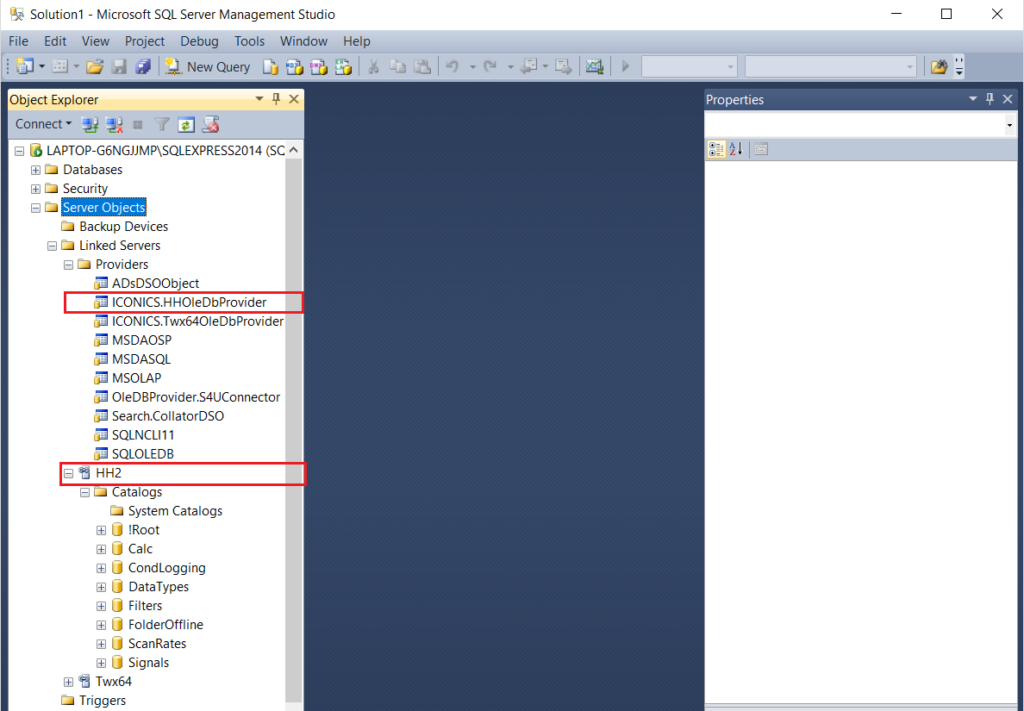
Pomimo, że Hyper Historian zapisuje dane historyczne do plików z rozszerzeniem .hhd, istnienie dołączonego serwera "HH2" w MS SQL Server pozwala na odpytywanie go tak, jak każdego innego serwera SQL .
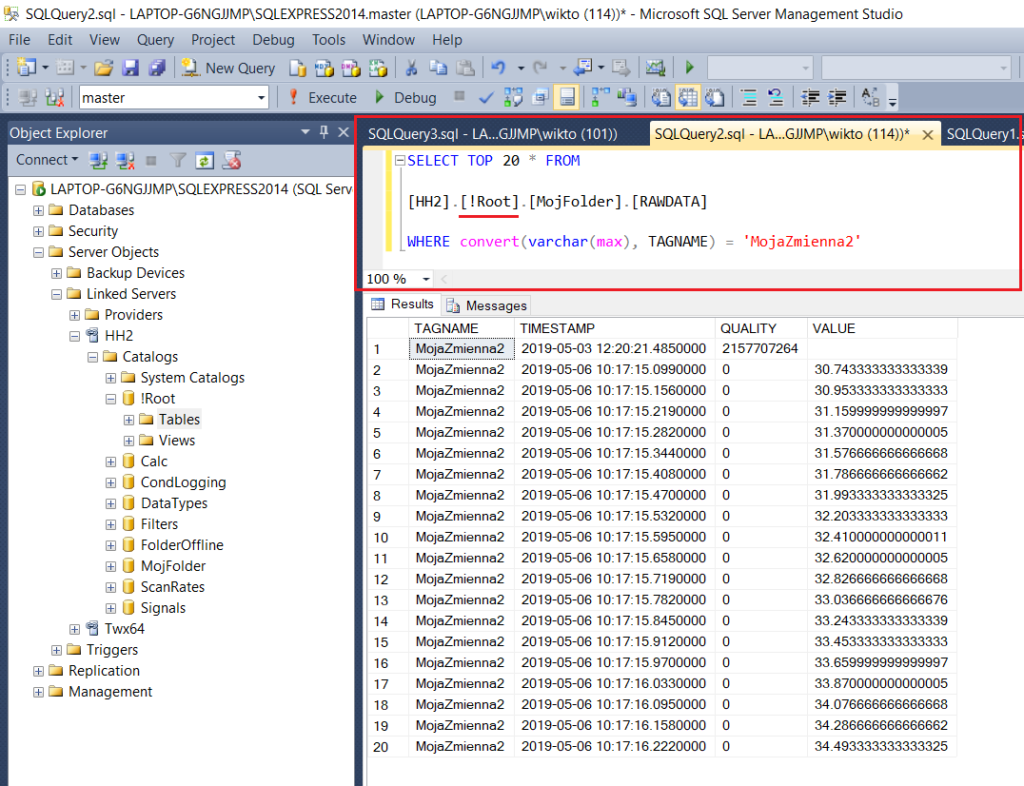
Aby wysłać zapytanie do dołączonego (zdalnego) serwera SQL, jakim jest tu Hyper Historian, należy użyć tzw. kwerend rozproszonych. Poniżej przedstawione są dwa sposoby, mówiące jak to zrobić.
Funkcja "OPENQUERY"
Po pierwsze, można posłużyć się funkcją tabelaryczną OPENQUERY. Jej składnia dla SQL Server jest następująca.
SELECT * FROM OPENQUERY( nazwa serwera powiazanego, ‘zapytanie SQL' )
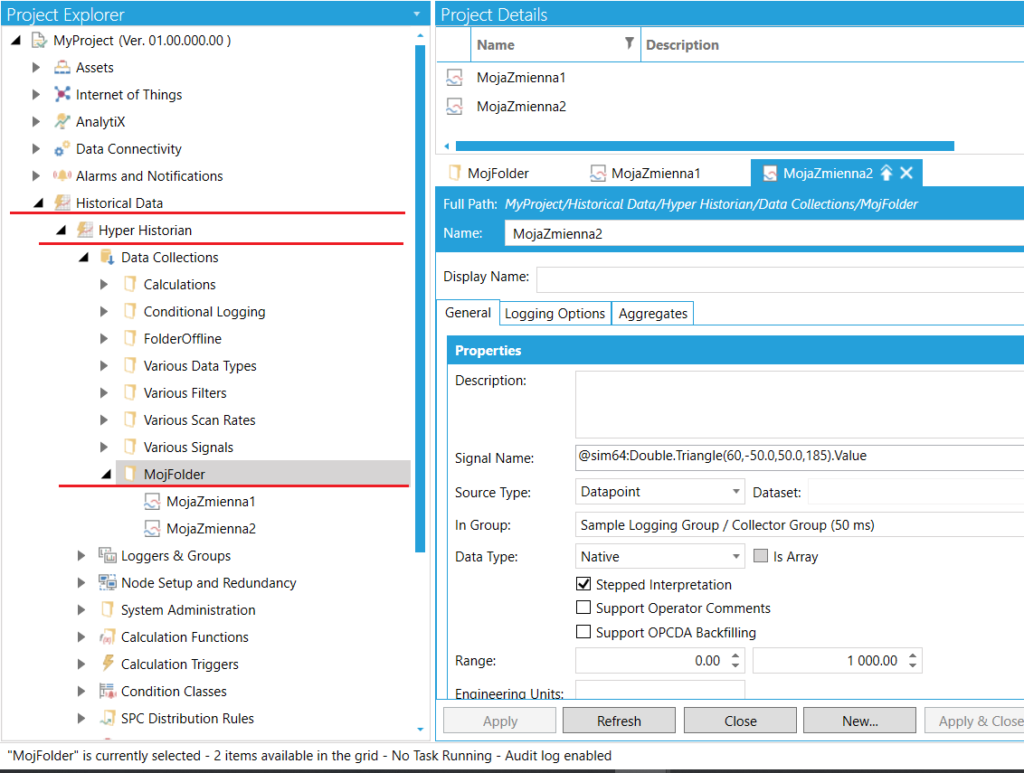
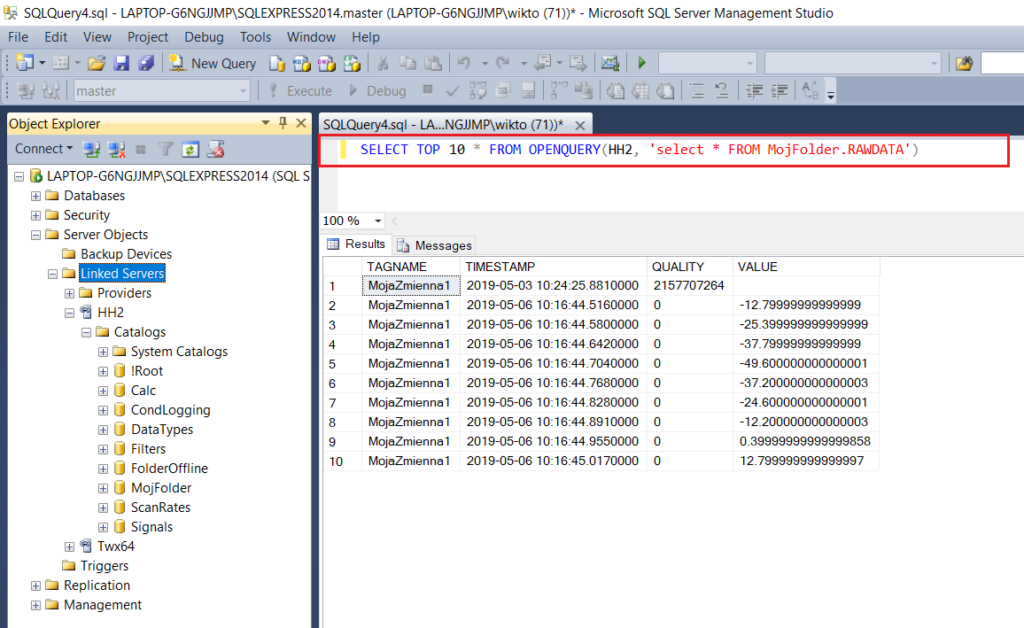
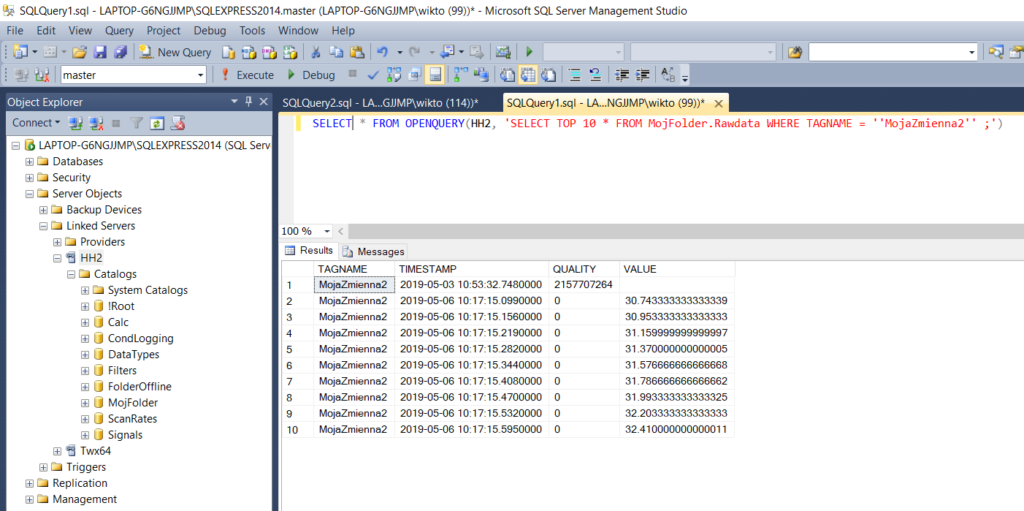
Posiadaną konfigurację Hyper Historian oraz przykład użycia kwerendy OPENQUERY przedstawiają poniższe zdjęcia.
|
Konfiguracja HyperHistorian |
SQL Linked Server Example 1 |
SQL Linked Server Example 2 |
Sterownik OLE DB do Hyper Historian obsługuje również kwerendy typu INSERT oraz UPDATE. Ponadto, silnik SQL od ICONICS ma zdefiniowane pewne domyślne procedury (ang. Stored Procedures). Są to gotowe szablony zapytań realizujących bardziej skomplikowane działania. Przykładem takiej procedury może być:
SELECT * FROM Signals.HDA_ANALOG( ‘2014-01-01 10:00:00', ‘2014-01-01 12:00:00', 300000, ‘Sine' ); .
Zwraca ona pewne wartości opisujące daną zmienną, jak na przykład maksimum, minimum lub średnią za dany okres czasu. Więcej przykładów zapytań SQL lub dostępnych gotowych procedur znajduje się w dokumentacjach GENESIS64.
Niniejszy wpis ma na celu przedstawienie zastosowania silnika SQL dla modułu archiwizacji od ICONICS. Nie porusza on kwestii technicznych dotyczących samego języka zapytań SQL. Więcej informacji na ten temat można znaleźć na przykład pod poniższym linkiem:
Szczególną uwagę należy zwrócić na fakt, że zapytanie SQL wprowadzanie jako argument kwerendy OPENQUERY musi znajdować się pomiędzy apostrofami. Co więcej, wtedy każdy apostrof będący częścią zapytania musi zostać podwojony. Na przykład: ... WHERE TAGNAME = ''Moja Zmienna2'' ... .
Zapytanie po jednoznacznej czteroczłonowej nazwie
Automatycznie dodany przy instalacji Hyper Historian'a serwer dołączony "HH2" jest widoczny w całym MS SQL Server. Dzięki temu odwołanie do konkretnych (mówiąc umownie) tabel Hyper Historian może następować poprzez podanie konkretnej ich lokalizacji - ścieżki dostępu. Składają się na nią następujące elementy.
[nazwa_serwera].[nazwa_bazy_danych].[nazwa_schematu].[nazwa.obiektu]
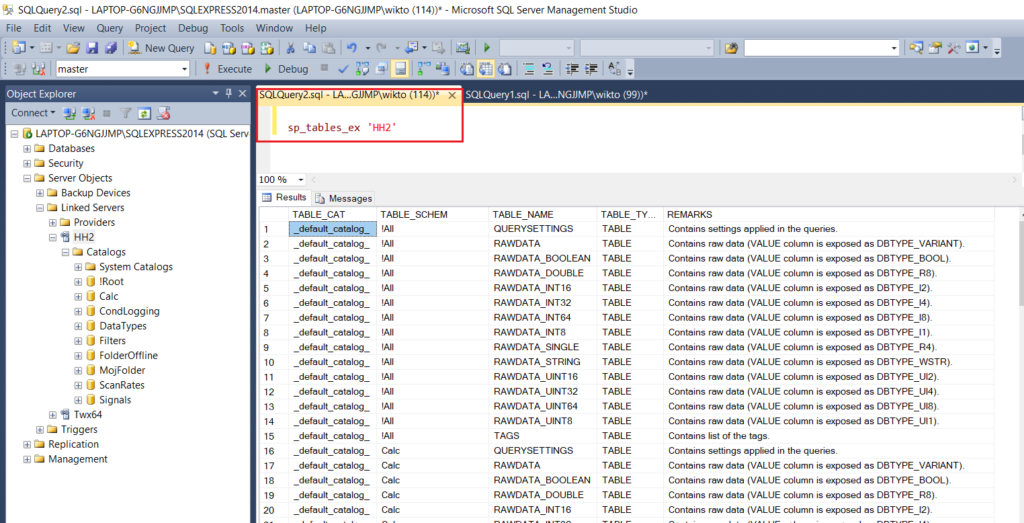
Strukturę serwera dołączonego HH2 sprawdza się poprzez wywołanie pewnych standardowych procedur. Należą do nich: sp_catalogs oraz sp_tables_ex. W wyniku ich działania można poznać odpowiednio: bazy danych oraz tabele Hyper Historian.
Mimo istnienia większej ilości baz danych w drzewku pod serwerem HH2 widocznym w SQL Management Studio, wszystkie dane są domyślnie przechowywane w bazie "!Root". Ponadto, domyślnie nazwy "!Root" i "_default_catalog_" (zob. zdj. poniżej) można stosować wymiennie.
|
Domyślne procedury Linked Servers |
SQL Linked Server Example 3 |
Dlatego, że wpis ten jest poświęcony głownie narzędziom od ICONICS, więcej informacji o strukturach danych w bazach SQL znajduje się pod poniższym linkiem.
Odczyt danych z systemu SCADA przy użyciu interfejsu OLE DB
Ten paragraf zawiera informacje o tym, jak wyświetlić dane z systemu SCADA wykorzystując aplikację komunikującą się po OLE DB. W przeciwieństwie do metody opisanej wyżej, ten sposób nie zakłada wykorzystania serwera dołączonego. Dalej, jako aplikacja wymieniająca dane za pomocą OLE DB, posłuży Microsoft Excel. Prezentowane tutaj rozwiązanie pozwoli w efekcie na wyświetlanie wartości historycznych pożądanej zmiennej OPC.
Konfiguracja SQL Server
Po pierwsze, należy utworzyć odpowiednią procedurę operującą na tabeli zawierającej wartości wszystkich tagów w SQL Server. Przykładem może być poniższy kod.
Create PROCEDURE dbo.HHRead @Tag nvarchar(30)
AS
DECLARE @TSQL nvarchar(max)
SET @TSQL =
‘select * from openquery(HH2, ''select * from “!Root"."!All".RAWDATA where TAGNAME = '''''+@Tag+''''''')'
print @TSQL
EXEC (@TSQL)
GO
Tworzy on procedurę przyjmującą jako parametr nazwę określonej zmiennej i w efekcie swego działania - zwracającą jej wartości.
Konfiguracja Excel
Następnie w programie Excel należy utworzyć źródło danych czerpiące informacje z zapytań Microsoft SQL. Użytkownik zostanie poproszony o wskazanie serwera SQL oraz opcjonalnie o podanie loginu i hasła.
Po wypełnieniu opcji konfiguracyjnych otworzy się nowe natywne okno programu Excel. Zawiera ono opcje pozwalające na wywołanie odpowiedniej procedury. W omawianym przypadku wywołanie procedury wygląda następująco.
{CALL master.dbo.HHRead (?)}
Jako bazę "pod którą" procedura zostaje wykonana wybrano bazę systemową "master" programu SQL Server. Pytajnik w powyższym wywołaniu oznacza, że występuje tu jeden parametr.
Idąc dalej, wyświetla się okno proszące użytkownika o podanie parametru. Należy pamiętać, że forma procedury użytej w tym wpisie narzuca podanie pełnej ścieżki do zmiennej w Hyper Historian.
|
Po wykonaniu powyższych czynności, w tymczasowym oknie powinien pojawić się podgląd pobranych danych. Po ponownym przejściu do arkusza Excel, samoistnie pojawia się okno importu pozwalające na wybór gdzie na arkuszu wyświetlą się dane. Raz dodane w ten sposób źródło danych można odświeżać za pomocą jednej opcji - "Refresh All" w zakładce "Data". Wymaga to jedynie powtórnego wprowadzenia wartości parametru (parametrów). |
OLE DB - dane z Hyper Historian w Excel |
Uwagi końcowe
W przypadku, gdy dane kwerendy wywołuje się na serwerze Hyper Historian, który zawiera znaczne ilości informacji, odpowiednie sformułowanie komendy może mieć kluczowe znaczenie. Na przykład zapytanie:
SELECT * FROM OPENQUERY( HH2, ‘select * from MojFolder.RAWDATA WHERE TIMESTAMP = ''2014-01-01 10:00:00'' ’)
spowoduje wyszukanie na serwerze dołączonym HyperHistorian wszystkich próbek z podanej chwili, a następnie wysłanie ich do głównego serwera SQL. Z drugiej strony, kwerenda:
SELECT * FROM OPENQUERY( HH2, ‘select * from MojFolder.RRAWDATA' )
WHERE TIMESTAMP = ‘2014-01-01 10:00:00'
wymusi już wysłanie całej zawartości folderu "Moj Folder" do głównego serwera SQL, a następnie przefiltrowanie tych danych na głównym serwerze.
Redundantna archiwizacja danych w systemie SCADA
Jak działa Hyper Historian?
Hyper Historian to narzędzie służące do pozyskiwania oraz archiwizacji dużej ilości danych czasu rzeczywistego. Aby poznać lepiej sposób jego działania, należy zdać sobie sprawę z istnienia jego dwóch podstawowych komponentów:
- Collector - łączy się ze źródłem danych w celu prowadzenia odczytu ze zdefiniowaną częstością, a następnie wysłania danych do logger'a,
- Logger - zapisuje otrzymywane dane w plikach binarnych na dysku komputera oraz zarządza tymi plikami.
Na każdym komputerze z zainstalowanym Hyper Historian'em użytkownik może dowolnie skonfigurować serwer logowania danych oraz kolektory wchodzące w skład tego narzędzia. Serwer logowania (w którego skład wchodzą jest jeden, natomiast liczba kolektorów jest limitowana jedynie licencją użytkownika. Co więcej, dzielą się one na dwa rodzaje:
- In-Process Collector - kolektor lokalny, niemogący działać zdalnie względem loggera,
- Standalone (Remote) Collector - samodzielny kolektor, który dodatkowo wspiera funkcję redundancji oraz może wysyłać dane do logger'a poprzez sieć.
Wpis ten porusza kwestię ustawienia redundancji na przykładzie dwóch PC z działającym oprogramowaniem GENESIS64 (mógłby to być również sam HyperHistorian). Komputery te znajdują się w jednej sieci LAN. Co więcej, każdy z nich pobiera dane z zewnętrznego serwera OPC UA.
W tym przypadku klientem będzie interfejs aplikacji GraphWorX (modułu wizualizacji) działający na jednym z tych komputerów - w ogólności mógłby to być trzeci komputer również podłączony do sieci LAN.
Podstawowe wymagania
Zgodna konfiguracja modułu HyperHistorian
Przy konfigurowaniu redundantnej archiwizacji w module Hyper Historian, serwer główny oraz zapasowy muszą posiadać taką samą konfigurację. Można to zapewnić w prosty sposób - wskazując dla obydwu serwerów tą samą bazę danych - najlepiej, znajdującą się w neutralnej lokalizacji.
W tym przypadku, konfiguracyjna baza danych dla obydwu serwerów Hyper Historian znajduje się na serwerze w chmurze. W rezultacie, wprowadzanie zmian w ustawieniach Hyper Historian na jednym serwerze powoduje automatyczne zmiany na drugim.
|
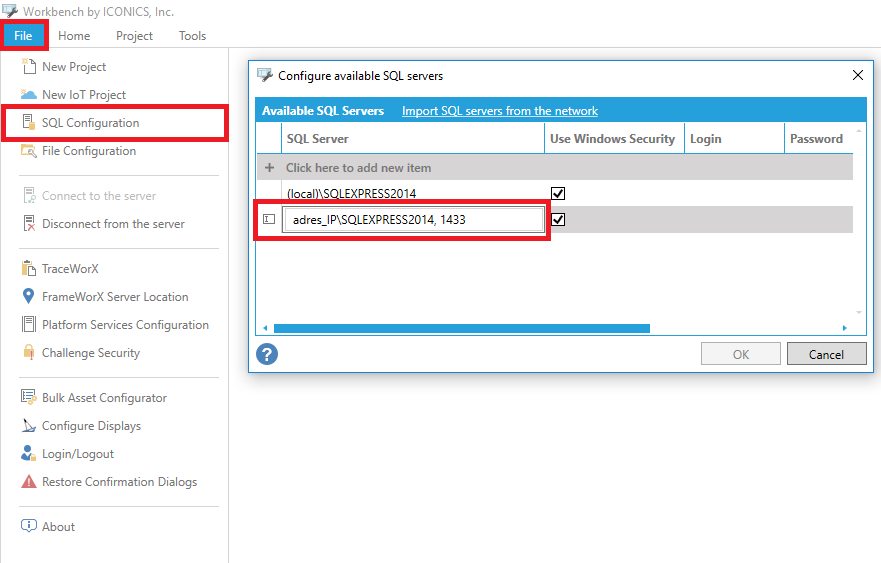
Aby dodać serwer SQL, z którego korzysta aplikacja GENESIS64, należy w oknie Workbench przejść do zakładki "File" oraz wybrać opcję "SQL Configuration". Następnie należy w wymagane pole wprowadzić poprawny łańcuch połączenia z serwerem SQL. <adresIP>\<nazwaSerwera>, numer portu Należy przy tym pamiętać, aby odblokować dla serwera w chmurze komunikację po wybranym porcie (np. 1433) oraz ustawić odpowiednie uprawnienia dostępu do docelowej bazy danych dla łączącego się użytkownika (odczyt i zapis). |
 |
| W celu wskazania bazy danych dla Hyper Historian należy wybrać PPM posiadany projekt w Workbench oraz użyć opcji "Configure Application Settings". W nowo otworzonym oknie dokonuje się przypisania baz danych do modułów GENESIS64. | 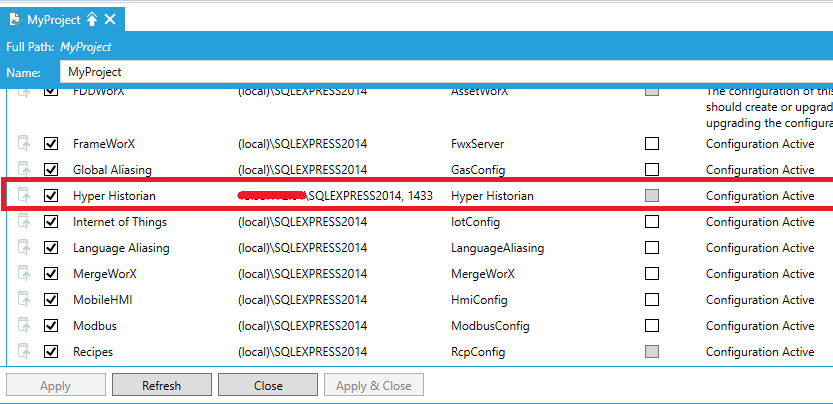 |
Synchronizacja czasu na serwerach SCADA
| Drugim podstawowym wymogiem jest zsynchronizowanie zegarów na komputerach PC. Nie jest to jednak zagadnienie związane ściśle z oprogramowaniem od ICONICS. Dokonuje się tego na poziomie systemu operacyjnego, a dla komputerów połączonych w sieci LAN można to zrobić w sposób przedstawiony niżej. |
|
Należy pamiętać, aby wykonać te działania dla obydwu komputerów obsługujących Hyper Historian, używając tego samego serwera do synchronizacji czasu.
Licencja Hyper Historian
ICONICS oferuje 3 różne typy licencji na moduł Historian: Express, Standard oraz Enterprise. W tym przypadku wymagana licencja to "Enterprise". Zapewnia ona wszystkie cechy licencji "Standard" (takie jak np. bibiloteki funkcji historycznych) oraz takie zalety jak:
- możliwość konfiguracji zdalnych samodzielnych kolektorów,
- redundancję systemu.
Schemat wzajemnych połączeń w systemie
|
Podsumowując, na system składają się:
Warto w tym miejscu dodać, że Hyper Historian z licencją "Enterprise" wspiera redundancję rozłożoną na wiele serwerów oraz zdalnych kolektorów. W tym jednak wypadku, gdy aplikacja działa na dwóch maszynach, najlepiej sprawdza się konfiguracja, gdzie do zapasowego systemu (Server B na rys.) przyporządkowany jest główny logger, a do głównego systemu (Server A) - główny kolektor. Dzieje się tak dlatego, gdyż teraz, w wyniku awarii serwera A lub B, przełączyć będzie się musiał jedynie jeden komponent. |
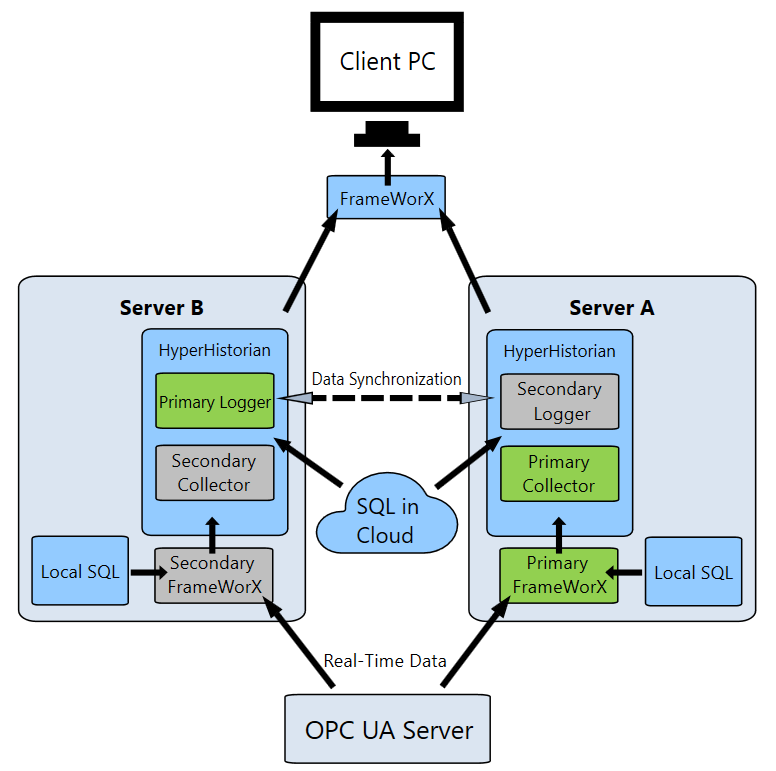
Redundantna archiwizacja w systemie SCADA ICONICS - schemat |
Należy również pamiętać, aby w wypadku posiadania redundantnych źródłowych serwerów OPC, główny kolektor działał na tej samej maszynie, co główny OPC Server. Zawsze lepiej jest pobierać dane ze źródła lokalnego, niż łączyć się z nim przez sieć.
Podsumowując, w prezentowanym rozwiązaniu istnieje jeden zewnętrzny serwer OPC działający na sterowniku PLC. Moduły komunikacyjne GENESIS64 działające na maszynach "Server A" i "Server B" - FrameWorX - łączą się z nim. Przekazują one następnie dane do kolektora Hyper Historian'a. Jednak w danym czasie tylko jeden kolektor jest aktywny. Kolejnym krokiem jest wysłanie danych z kolektora do logger'a.
Aplikacja kliencka będąca również programem GENESIS64 łączy się za pośrednictwem sowojego FrameWorX'a z obecnie aktywnym loggerem.
Konfiguracja redundantnej archiwizacji w systemie SCADA
Tę część wpisu rozpocznie skonfigurowanie modułu Hyper Historian. Pamiętając, że Historian'y działające na Serwerach A i B korzystają ze wspólnej bazy danych, wystarczy jeśli ustawienia zostaną poczynione na jednej maszynie.
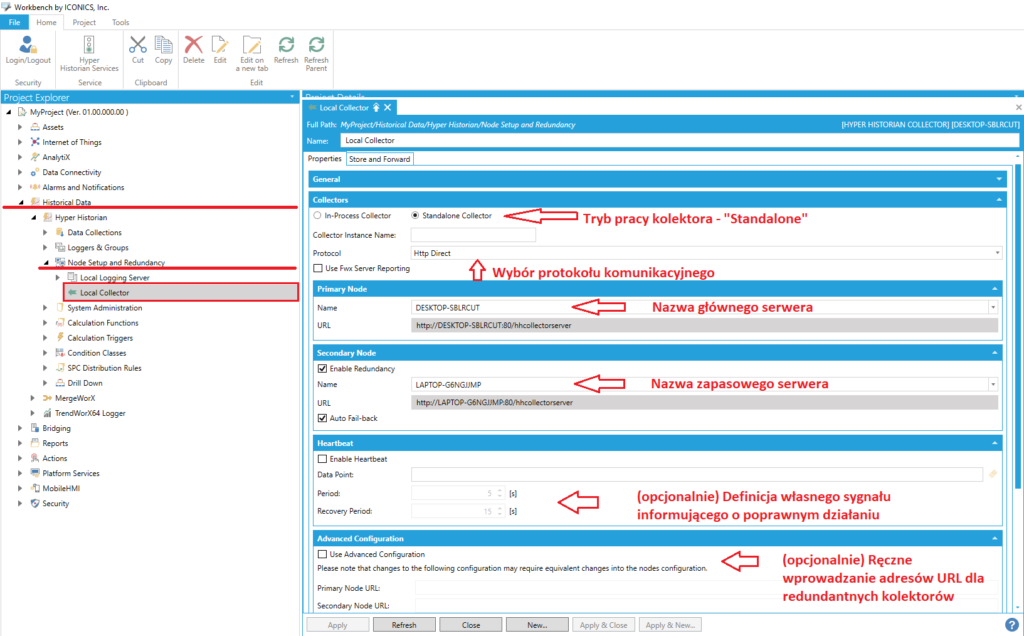
Pierwsze z poniższych zdjęć odnosi się do redundantnej samodzielnej pary kolektorów. Użytkownik definiuje dla nich takie parametry, jak na przykład adres IP lub nazwy serwerów z działającymi kolektorami, czy opcję automatycznego powrotu na serwer główny w przypadku wznowienia jego działania po awarii (opcja "Auto Fail-back" na zdjęciu).
Adresy URL serwerów generują się automatycznie - użytkownik wypełnia jedynie pole "Name". W razie odstępstw automatycznych nazw od rzeczywistości, po wybraniu opcji "Use Advanced Configuration", można wprowadzić te adresy ręcznie.
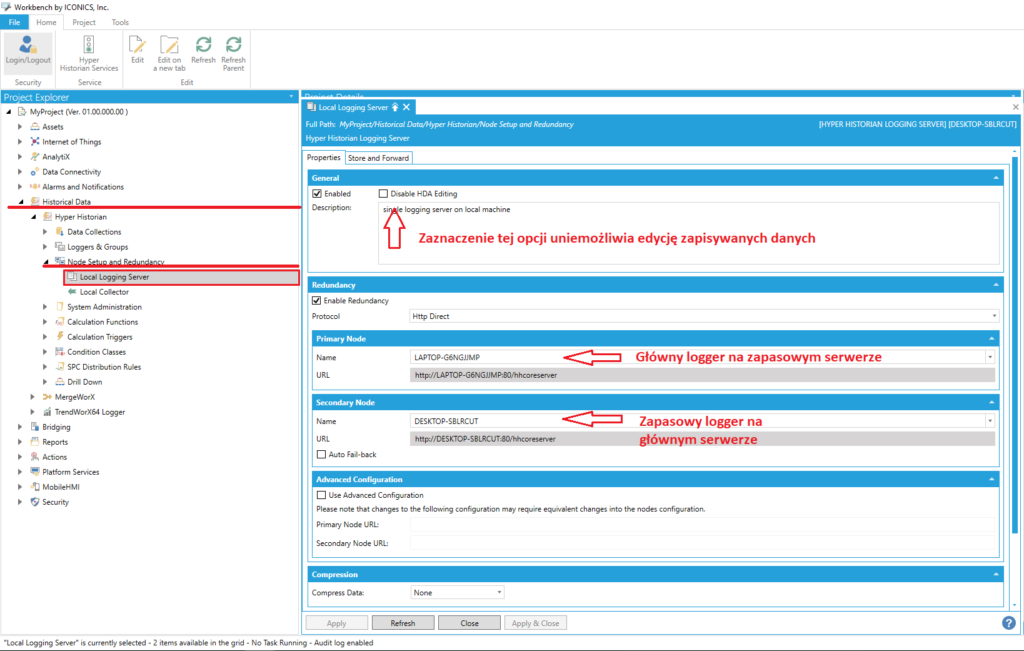
Drugie zdjęcie dotyczy ustawień logger'ów. Większość opcji jest analogiczna do tych powyżej. Pamiętać należy w tym przypadku jedynie o konieczności przyporządkowania głównego logger'a do zapasowego serwera.
|
Konfiguracja Kolektora - podstawowe opcje (kliknij) |
Konfiguracja redundantnego logger'a (kliknij) |
|
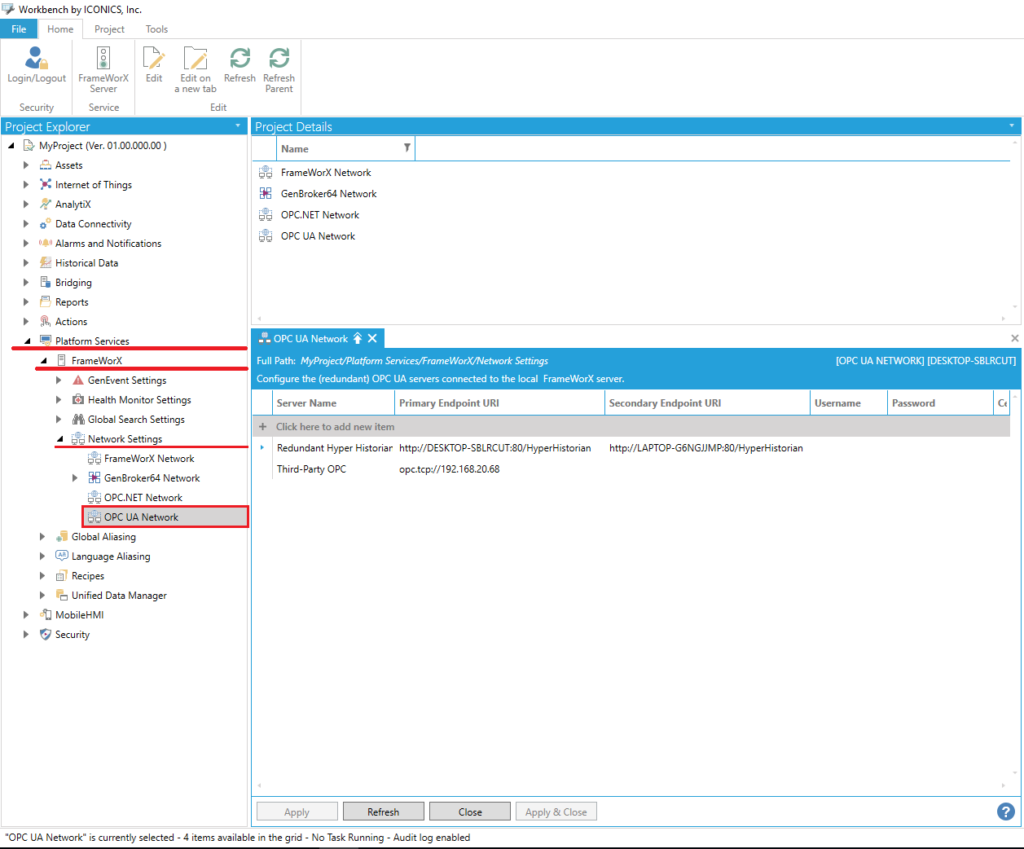
Trzeci krok polega na skonfigurowaniu sieci komunikacji dla narzędzia FrameWorX. Aby wymiana danych zachodziła poprawnie, należy zdefiniować połączenie ze źródłowym serwerem OPC oraz serwerami HyperHistorian. Dokonuje się tego jak na zdjęciu poniżej. Dla serwera OPC podaje się w tym przypadku jeden adres URI. Element symbolizujący połączenie z serwerami HyperHistorian ma natomiast dwa adresy - zgodne z redundantną architekturą systemu. Jeśli dwa serwery z zainstalowanym oprogramowaniem GENESIS64 współdzielą konfiguracyjną bazę danych dla FrameWorX, ustawienia tego narzędzia powinny być dla nich identyczne. Jednak dla tego projektu, konfigurując FrameWorX na serwerze zapasowym adresy "Primary-" i "Secondary Endpoint URI" powinny zostać zamienione miejscami.
|
|
Oczywiście nazwy połączeń w tej sekcji muszą być identyczne dla obydwu serwerów. Jeśli w sieci istnieje trzeci komputer - kliencki, dla niego trzeba dodać połączenie symbolizujące parę redundantnych Historian'ów - pierwsza pozycja na zdjęciu powyżej.
|
Ostatnim krokiem jest dodanie do konfiguracji HyperHistorian pożądanej zmiennej pochodzącej z serwera OPC. W tym miejscu ujawnia się potrzeba zdefiniowania połączenia z serwerem OPC z identyczną nazwą dla każdego GENESIS64. Odpowiednie ustawienia oraz lokalizację sygnału w wyszukiwarce danych przedstawia poniższe zdjęcie. |
|
Obsługa redundancji archiwizacji w systemie SCADA od ICONICS
Śledzenie stanu licencji i pracy komponentów
|
Podgląd pracy serwerów HyperHistorian - aktualny stan logger'ów oraz kolektorów - można uzyskać za pomocą narzędzia MonitorWorX Vierwer służącego do śledzenia stanu licencji. Posiada ono zakładkę "Redundancy" pozwalającą na obserwowanie w czasie rzeczywistym, które z redundantnych komponentów systemu GENESIS64 są aktywne w danej chwili. Co więcej, informacje te dotyczą nie tylko archiwizacji, ale również wszystkich sieci OPC Classic lub OPC UA zdefiniowanych w systemie. |
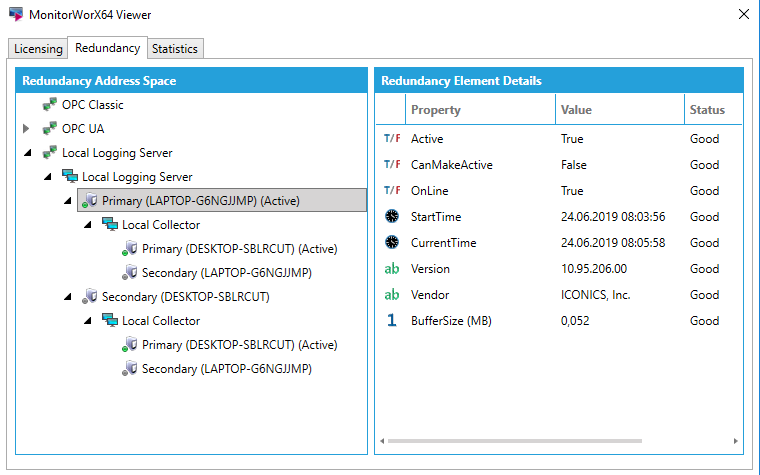 Stan redundantnej archiwizacji - MonitorWorX Viewer Stan redundantnej archiwizacji - MonitorWorX Viewer |
Na zdjęciu powyżej widać część struktury projektowanego systemu odpowiedzialną za redundantną archiwizację. Zgodnie z prezentowanymi informacjami, obecnie aktywnym loggerem jest ten główny (pracujący na komputerze LAPTOP-G6NGJJMP - serwer zapasowy), natomiast aktywny kolektor pracuje na maszynie DESKTOP-SBLRCUT (i jest on również głównym kolektorem).
|
Dodatkowo, po wybraniu z drzewka dowolnego elementu, w prawej części okna MonitorWorX Viewer ukazuje się zestaw informacji na jego temat. Na redundantną pracę systemu wskazują również dane z innych zakładek MonitorWorX'a - na przykład te informujące o wykorzystaniu licencji "Enterprise" dla HyperHistorian lub pracy samodzielnego kolektora. |
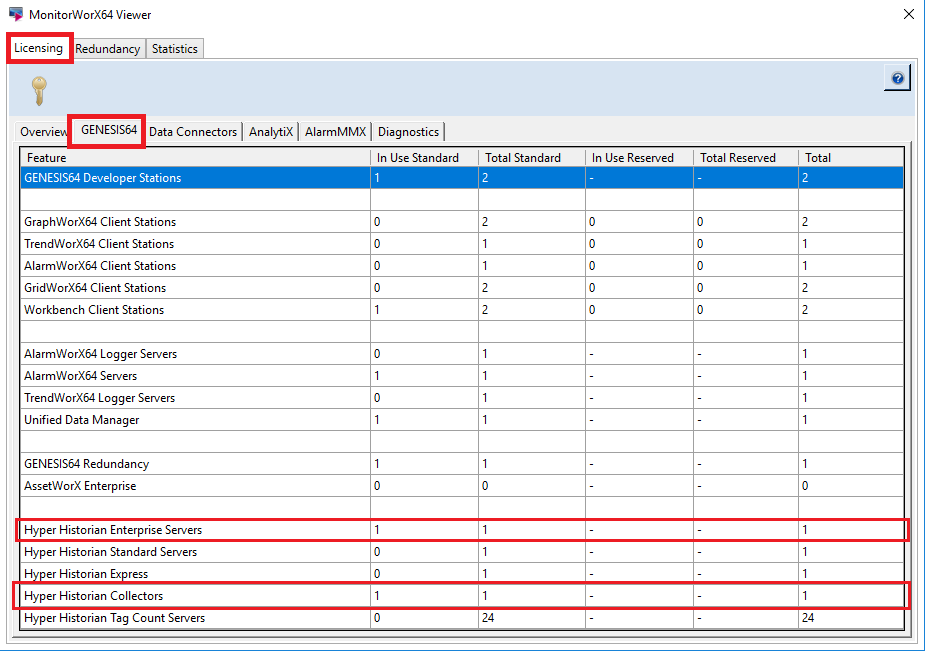 Podgląd licencji dla Hyper Historian - MonitorWorX Viewer Podgląd licencji dla Hyper Historian - MonitorWorX Viewer |
Potrzebne usługi systemowe
System SCADA od ICONICS działa dzięki istnieniu kilkunastu usług systemowych odpowiedzialnych za działanie poszczególnych narzędzi.
Dostęp do nich uzyskuje się zwyczajnie z menu wyszukiwania Windows. Te, które dotyczą Hyper Historian'a to:
- ICONICS Hyper Historian Logger - odpowiedzialna za zapis danych na dysk (działanie logger'a);
- ICONICS Hyper Historian Collector - ta natomiast umożliwia działanie samodzielnych kolektorów (nawet przy nieredundantnym systemie).
Prezentacja rezultatów
| Działania przeprowadzane są na maszynie DESKTOP-SBLRCUT (zapasowy logger, główny kolektor). Symulacje awarii następują poprzez cykliczne wyłączanie odpowiednich usług systemowych, opisanych wyżej. Wszystkie zmiany obserwowane są za pomocą MonitorWorX Viewera. | Redundantna archiwizacja w systemie SCADA - podstawy obsługi |
Rozproszona archiwizacja danych
Rozproszona archiwizacja w systemie SCADA ICONICS działa dzięki Zdalnym Kolektorom. Dowiedz się czym one są i jak współpracują z serwerem Hyper Historian.
Działanie modułu archiwizacji HyperHistorian
Moduł archiwizacji Hyper Historian od ICONICS dzieli się na dwa podstawowe komponenty. Pierwszy z nich to Collector - jest to usługa działająca w celu pobierania danych ze źródła, normalizowania ich do postaci zmiennej OPC oraz (ewentualnie) wykonywania wstępnych obliczeń na danych.
Drugim składnikiem jest natomiast Logger. Odpowiada on za zapis danych w plikach binarnych na dysku komputera. W jego zakresie leży również zarządzanie tworzonymi plikami. Informacje do Logger'a wysyłane są bezpośrednio przez Kolektor (Collector).
Czym są Zdalne Kolektory?
Jak wspomniano we wstępie, rozproszona archiwizacja w systemie SCADA ICONICS opiera się o Zdalne Kolektory (ang. Remote Collectors). To pojedyncze narzędzia (usługi) instalowane osobno, na danej maszynie działającej z systemem Windows. Ich zadanie jest takie samo, jak dla standardowych (loklanych) odpowiedników. Różnią się jednak możliwością samodzielnego działania.
Zdalny kolektor działający na tym samym komputerze, co źródłowy serwer OPC, pobiera z niego dane, a następnie wysyła je poprzez sieć do głównego serwera HyperHistorian.
Dlaczego rozproszona archiwizacja w systemach SCADA jest istotna?
Można sobie wyobrazić, że sieci lokalne (zamknięte) - wewnątrzzakładowe, obsługiwane przez pojedyncze routery mogą mieć problem z przesyłem dużej ilości danych w czasie rzeczywistym. Szczególnie wtedy, gdy dane te są pobierane z wielu elementów wyposażenia.
Sytuacja taka jest wysoce niepożądana, a nawet bezcelowa w przypadku, gdy w praktyce nie potrzeba znać wszystkich wartości danej zmiennej, a jedynie pewne średnie parametry jej przebiegu.
| Można przykładowo wyobrazić sobie następującą sytuację. Na Komputerze A działa serwer OPC, który zbiera szybkozmienne odczyty z urządzenia podpiętego lokalnie do tego komputera. Odczyty te prowadzi się w odstępie 500ms i na bieżąco wysyła do głównego serwera Hyper Historian, działającego na Komputerze B. Na Komputerze B, odczyty te są zbiera Lokalny Kolektor, który oblicza ich dokładną średnią za okres 1 minuty i tylko tą wartość zapisuje się na dysku. | 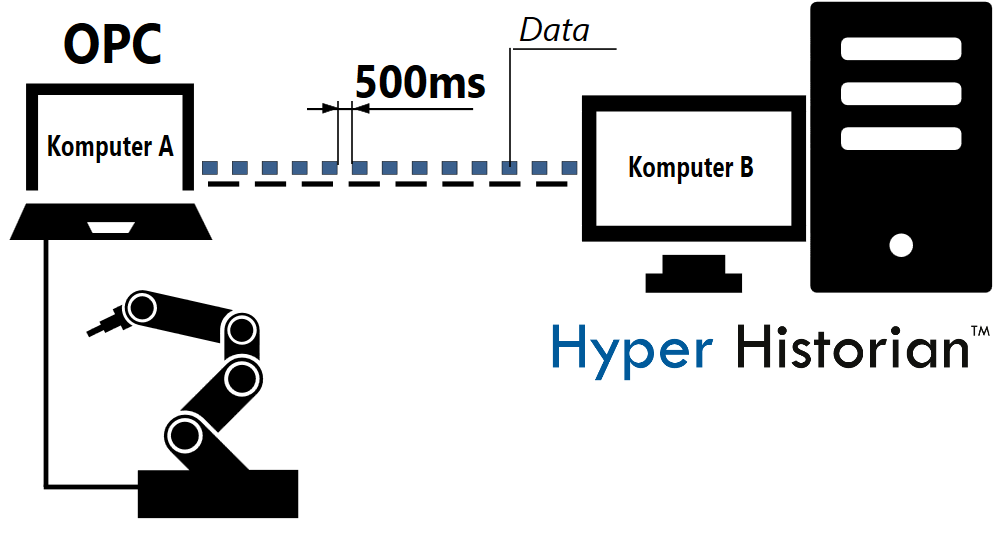 Schemat standardowej archiwizacji w systemie SCADA Schemat standardowej archiwizacji w systemie SCADA |
Nie trudno w tym przypadku zauważyć pewną nieefektywność. Przez okres 1 minuty tylko to jedno urządzenie prześle aż 120 próbek danych. Biorąc pod uwagę fakt, że na taki okres czasu tylko 1 wartość jest zapisywana (średnia), można dojść do wniosku, że 119 próbek przesyła się bezcelowo.
| ICONICS stworzyło rozwiązanie mające na celu usprawnienie tego procesu. Posiadając zainstalowaną na Komputerze A usługę Zdalnego Kolektora, potrzebne obliczenia (wyciągnięcie średniej) można wykonać lokalnie na nim. W wyniku tego, poprzez sieć wysyłana jest tylko jedna wartość na każdą minutę - wynik obliczeń. Warto podkreślić, że dzięki takiemu podejściu, można przesłać dane pochodzące ze 120 różnych urządzeń, obciążając sieć w taki sam sposób, jak za pierwszym razem. | 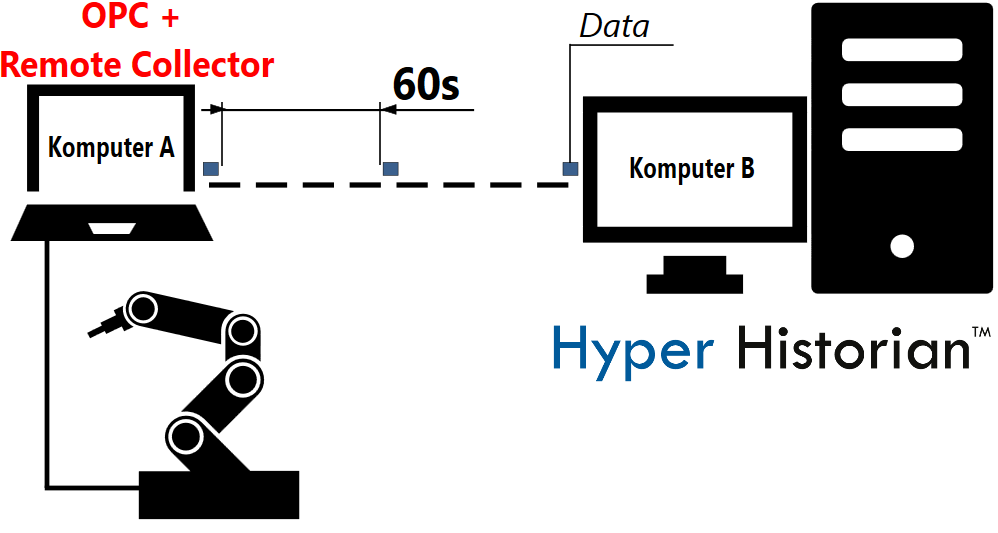 Rozproszona archiwizacja SCADA - schemat Rozproszona archiwizacja SCADA - schemat |
Konfiguracja zdalnej archiwizacji
Niezbędne zasoby
Aby móc korzystać z funkcji Zdalnych Kolektorów (ang Remote Collectors) wymagana jest licencja typu Enterprise dla modułu Hyper Historian.
W celu zainstalowania usługi Logger'a - zapisu danych na dysk komputera w głównej lokalizacji, potrzebna jest pełna instalacja Hyper Historian. Nieważne czy jest to instalacja samodzielnego Historian'a, czy jest on częścią całego pakietu SCADA GENESIS64. Wynika to z faktu, że nie ma "Zdalnych Logger'ów" - są to centralne, główne narzędzia.
Zdalny Kolektor instaluje się z płyty DVD z Hyper Historian.
Ustawienia wstępne
|
Aby system w takiej postaci działał prawidłowo, należy zsynchronizować czas na maszynach obsługujących logger'y i kolektory. Działania te nie są związane z narzędziami od ICONICS i mogą się różnić w zależności od czynników, takich jak:
W momencie, gdy komputery mają dostęp do Internetu, sprawa jest łatwa. Wystarczy w ustawieniach w Panelu Sterowania wskazać im ten sam serwer internetowy przechowujący aktualny czas. |
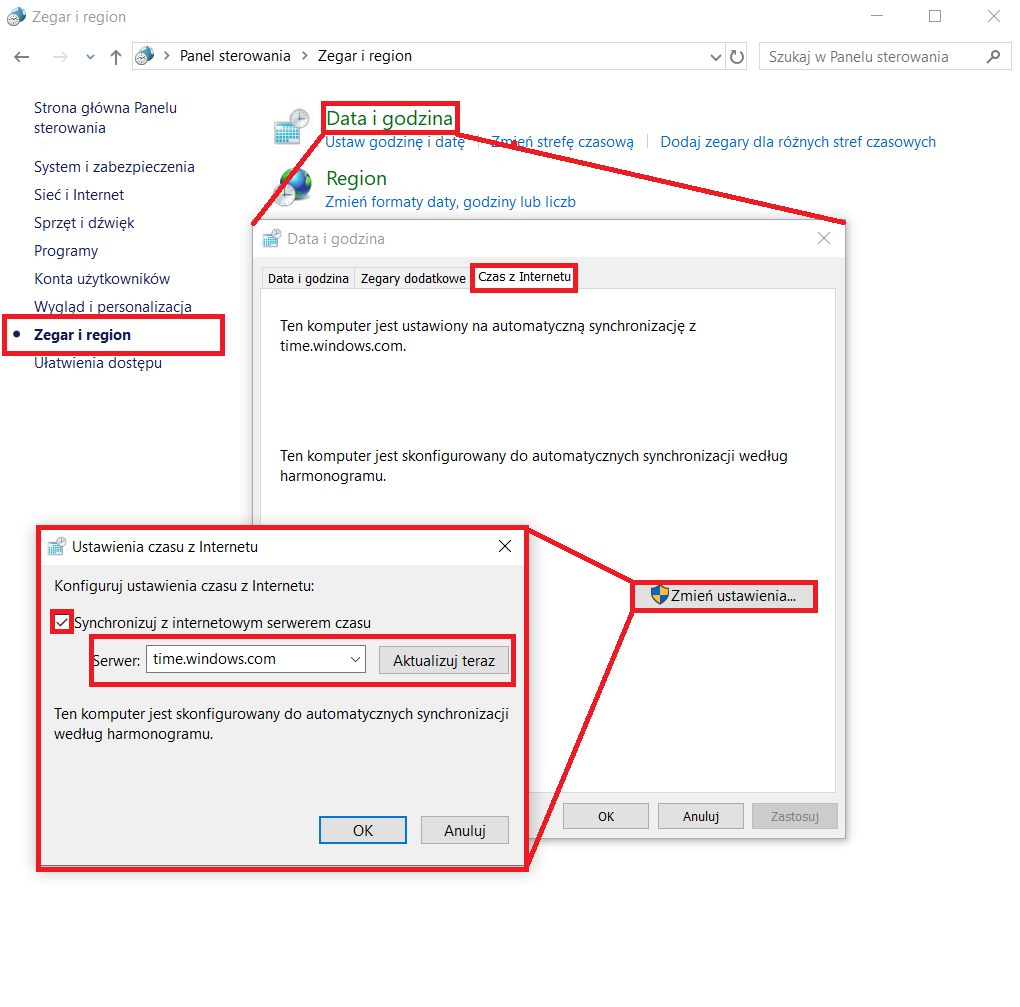 |
Jeśli komponenty HyperHistorian nie komunikują się ze sobą, może wynikać z blokowania przepływu danych na określonym porcie przez Firewall. Czasem należy też zmienić ustawienia usługi UAC (User Account Control) w systemie.
Konfiguracja Zdalnego Kolektora
Odpowiednia opcja instalacyjna znajduje się na płycie DVD z HyperHistorian. Nosi ona nazwę "Hyper Historian Collector".
|
W tym przypadku wybrano instalację kolektora dla 64 bitowego systemu. Należy również pamiętać, że ta instalacja nie wymaga połączenia z bazą SQL. Przy takiej konfiguracji systemu, wszystkie informacje odnośnie ustawień znajdują się w bazie SQL głównego serwera Hyper Historian. Główny serwer wysyła te dane do Kolektora przy każdym uruchomieniu, lub po każdej ich edycji. |
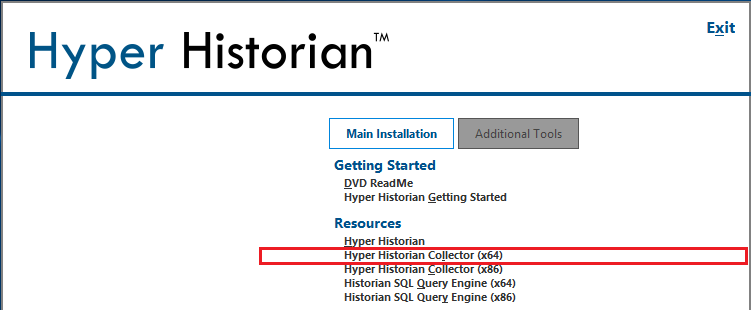 |
W przypadku, gdyby instalowany był pełny serwer Hyper Historian, należałoby przy instalacji wskazać serwer SQL do przechowywania konfiguracji.
Ostatnią ważną rzeczą jest fakt, że do prawidłowego działania archiwizacji na każdej maszynie musi działać taka sama wersja oprogramowania i update'u.
Powyższe kroki wykonuje się na maszynie zdalnej, zbierającej dane z urządzenia i obliczającej wymagane parametry. Kolejne etapy konfiguracji Zdalnego Kolektora wykonuje się już na głównym serwerze.
Dodanie zdalnego kolektora do konfiguracji Hyper Historian
|
Nowy kolektor dodaje się w środowisku Workbench, w lokalizacji pokazanej na poniższym zdjęciu. Z ważniejszych opcji konfiguracyjnych, użytkownik powinien przede wszystkim zaznaczyć:
|
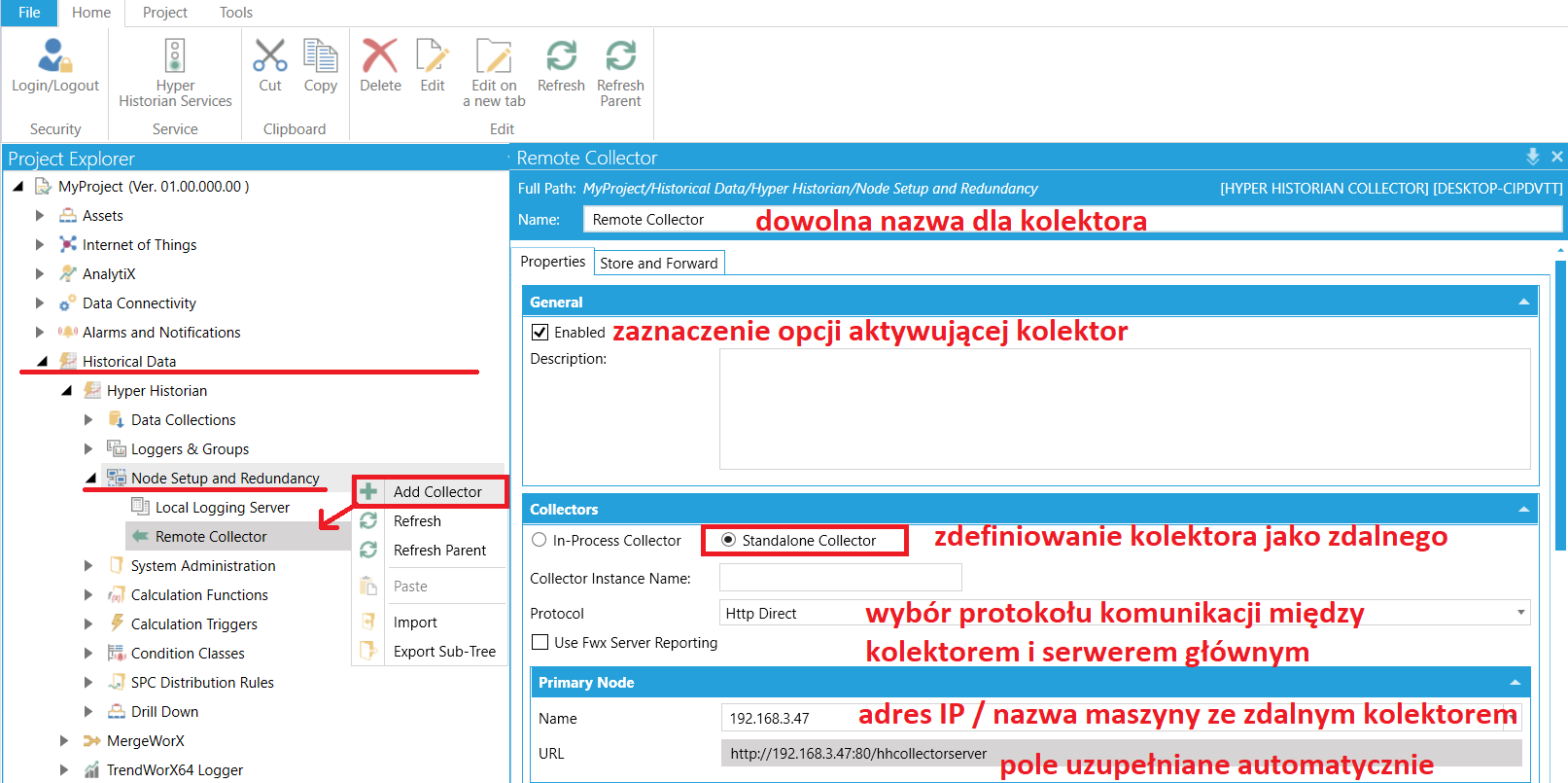 |
Wybierając protokół komunikacyjny, należy odczytać z pola "URL" port, którego on używa, a następnie odblokować komunikację przez Firewall dla niego.
Utworzenie odpowiedniej struktury archiwizacji
Pierwszą rzeczą jest dodanie loggera do systemu (tu posłużono się domyślnym przykładem "Data Logger" implementowanym automatycznie podczas instalacji).
Następnie "pod" danym logger'em należy utworzyć "Grupę Archiwizacji" (logowania danych) oraz przypisać do niej tego logger'a. Do nowo utworzonej grupy archiwizacji trzeba przypisać nową Grupę Kolektora. Jest to instancja wybranego kolektora, dla której podaje się pewne parametry pozyskiwania danych, jak np. okres odczytu, czy okres czasu, za który oblicza się pożądane wskaźniki.
|
Użytkownik może utworzyć dowolną ilość takich instancji dla jednego kolektora, a także tworzyć instancje dla innych kolektorów w obrębie tej samej grupy. Na filmie utworzono jedną instancję Zdalnego Kolektora. Zgodnie z przykładem opisanym na początku artykułu, pobiera ona próbki danych co 500 ms, i wykonuje obliczenia parametrów przebiegu zmiennych za okres 1 minuty. |
Struktura rozproszonej archiwizacji w Hyper Historian |
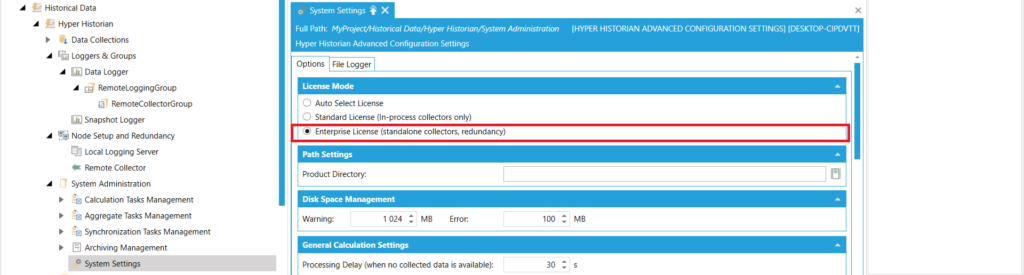
Licencja Hyper Historian
Aby upewnić się, że Hyper Historian pracuje z odpowiednią licencją, należy przejść do zakładki "System Administrtion"->"System Settings" oraz wybrać licencję "Enterprise".
 Rozproszona archiwizacja SCADA - wybór licencji dla Hyper Historian
Rozproszona archiwizacja SCADA - wybór licencji dla Hyper Historian
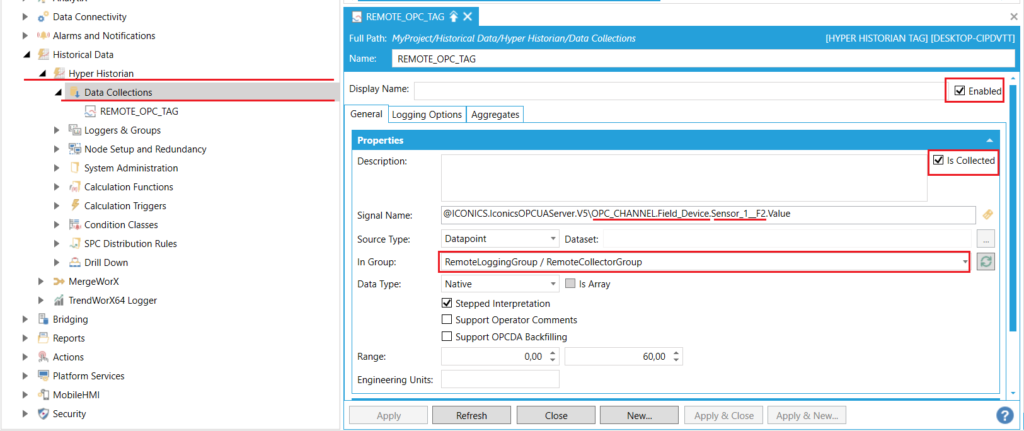
Dodanie archiwizowanych zmiennych
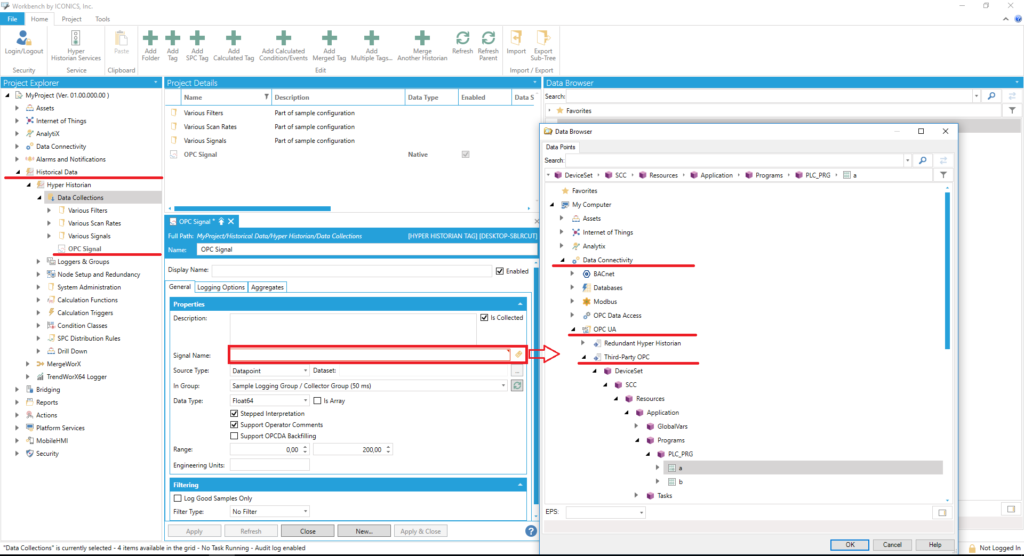
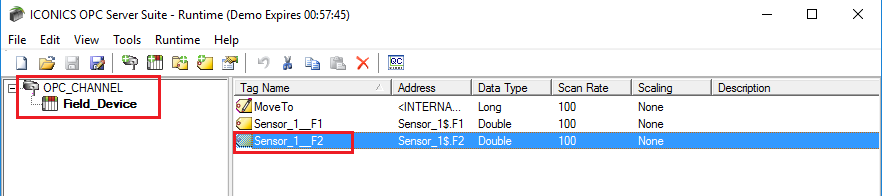
Dodając taką zmienną, trzeba przypisać ją do odpowiedniej Grupy Kolektora (tu: "RemoteCollectorGroup" ). Dokonuje się tego również z poziomu głównego serwera. Ścieżkę do zmiennej można wprowadzić ręcznie, wpisując lokalny łańcuch połączenia z serwerem OPC (tak, jak "widzi go" Zdalny Kolektor).
Poniższe zdjęcia przedstawiają dla przykładu:
- posiadaną konfigurację OPC Serwera - ICONICS OPC Server v5, zainstalowanego na zdalnej maszynie,
- ustawiania archiwizowanej zmiennej w Workbench pozwalające na jej odczyt.
|
|
 Archiwizowana zmienna Archiwizowana zmienna |
Prezentacja działania systemu
|
Pokazana wyżej zmienna symuluje sygnał sinusoidalny w zakresie <0, 50>. Została ona skonfigurowana tak, aby generować 120 próbek na pełen okres, każda co 500ms. Wynika z tego, że okres tego sygnału to 1 minuta. Do powyższej zmiennej dodano jeszcze jedną - spełniającą założenia z początku artykułu. Jej konfiguracja jest taka sama, jednak zaznaczono tam również opcję o zliczaniu średniej wartości tej zmiennej za okres 1 minuty (zamiast przesyłania wszystkich próbek). |





















