

Spis Treści
Bezpieczna komunikacja podczas archiwizacji - SCADA i HTTPS
Krótko o HTTPS
HTTPS to nieco zmieniona wersja popularnego w komunikacji klient-serwer protokołu HTTP. W przeciwieństwie do swojego standardowego odpowiednia, realizuje on szyfrowaną wymianę danych. Standardowo, w protokole sterowania transmisją TCP, działa on na porcie 443.
Do szyfrowania wykorzystuje on protokołu SSL lub TLS (będący rozwinięciem tego pierwszego). One wdrażają natomiast takie rozwiązania, jak szyfrowanie asymetryczne oraz certyfikaty X.509. Tak więc protokół HTTPS wykorzystuje się powszechnie do ochrony przed przechwytywaniem oraz manipulacją nad przesyłanymi danymi.
Bezpieczna komunikacja w systemie SCADA
W jednym z poprzednich wpisów skonfigurowano Zdalny Kolektor, który łącząc się z głównym serwerem Hyper Historian, wysyła do niego dane pochodzące z odległego urządzenia. Lektura tamtego wpisu może pomóc w lepszym zrozumieniu zamieszczonych tu treści.
Podczas dokonywania ustawień Zdalnego Kolektora w środowisku konfiguracyjnym Workbench, użytkownik był w stanie wskazać wiele sposobów komunikacji z nim. Jednak nie wszystkie z nich są całkowicie bezpieczne.
Sposoby wymiany informacji ze Zdalnym Kolektorem
Przede wszystkim należy zaznaczyć, że system SCADA od ICONICS wspiera dwa rodzaje połączeń między swoimi komponentami:
- bezpośrednie,
- z wykorzystaniem natywnego narzędzia do komunikacji - FrameWorX, które integruje się ze standardowymi protokołami.
Jak zostało pokazane we wpisie, do którego link zamieszczono wyżej, przy ustawianiu komunikacji ze zdalnym kolektorem, możliwe do wyboru są następujące protokoły:
|
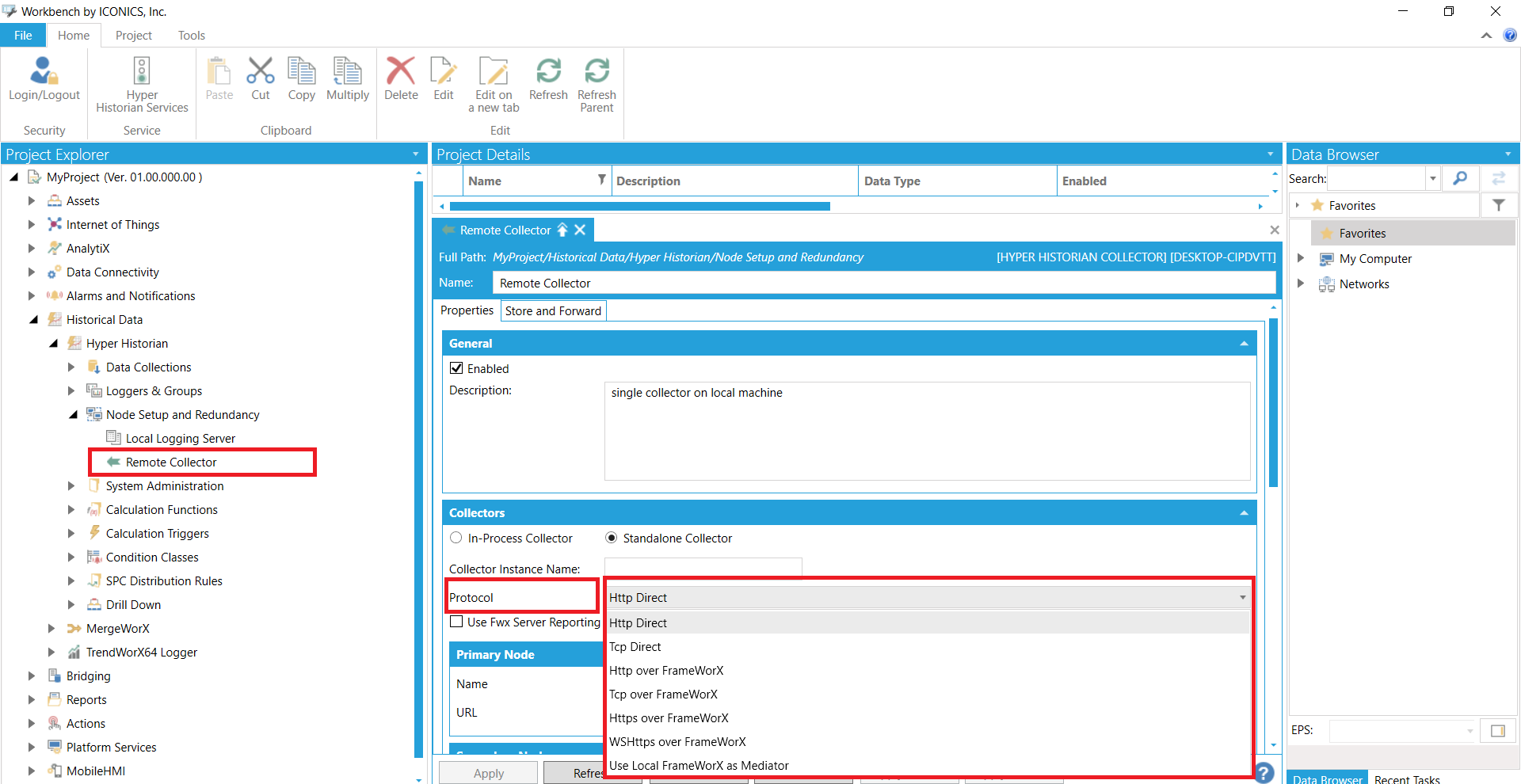 Protokoły wymiany informacji w module Hyper Historian Protokoły wymiany informacji w module Hyper Historian
|
Dwa ostatnie z wyżej wymienionych można uznać za bezpieczne, gdyż stosują szyfrowaną wymianę informacji. HTTPS pozwala na wydajne zabezpieczenie komunikacji "klient-serwer", podczas gdy WS-HTTPS stosuje się przy równorzędnej komunikacji dwóch komputerów.
Implementacja komunikacji po HTTPS w systemie
Komunikacja po HTTPS wymaga użycia jednego certyfikatu powiązanego z serwerem. Klient próbujący połączyć się z tym serwerem ma możliwość zaakceptowania tego certyfikatu i zabezpieczenia połączenia, gdy uzna, że posiada ten certyfikat wśród zaufanych. Uwierzytelnianie działa tak, że klient sprawdza wiarygodność serwera, z którym się łączy. Dlatego też ta metoda komunikacji jest idealna w sytuacjach, gdzie następuje połączenie z serwerem z poziomu maszyny klienckiej.
W posiadanym przykładowym systemie, na dwóch osobnych maszynach działają:
- pełny pakiet GENESIS64 z Hyper Historian,
- Zdalny Kolektor.
W tym przypadku to maszyna ze Zdalnym Kolektorem będzie serwerem danych, do którego podłączać się będzie klient - Logger modułu Hyper Historian.
Pierwszym krokiem będzie więc utworzenie odpowiedniego certyfikatu na maszynie z Kolektorem. Będzie to samodzielnie podpisany (self-signed) certyfikat, nie poświadczony przez żaden Urząd Certyfikacji. Takie certyfikaty można z powodzeniem stosować w obrębie sieci lokalnych. Jako, że brak tu poświadczenia ze strony zewnętrznych Urzędów Certyfikacji użytkownik musi sam zdecydować, którym wydawcom można zaufać.
Certyfikat na maszynie ze Zdalnym Kolektorem
Jak opisano to w artykule podlinkowanym na początku tego wpisu, w posiadanym systemie działa samodzielny kolektor na oddzielnej maszynie. Dalsze kroki przedstawiają więc postępowanie w przypadku, gdy użytkownik posiada maszynę z samym kolektorem, bez innych komponentów od ICONICS.
Wraz z usługami ICONICS instaluje się program pozwalający na utworzenie certyfikatu X.509. Uruchamia się go z poziomu "Wiersza polecenia" (Menu Start->Wyszukaj->cmd). Wiersz polecenia należy otworzyć z uprawnieniami administratorskimi.
Następnie użytkownik powinien przejść za pomocą Wiersza Polecenia do katalogu:
C:\Program Files\ICONICS\GENESIS64\InstCert
(chyba że domyślna lokalizacja instalacji pakietu ICONICS jest inna).
Kolejnym krokiem jest wywołanie następującej komendy.
makecert -a sha1 -n "CN=CollectorComputerName" -sr LocalMachine -ss My -r -sky exchange -pe -sk MarkContainerName
Spowoduje ona wywołanie działania programu "makecert", natomiast dodatkowe parametry zapewnią utworzenie certyfikatu w odpowiedniej lokalizacji oraz o odpowiednich właściwościach.
|
W tym przypadku będzie to certyfikat ważny w obrębie całej maszyny lokalnej (bez znaczenia jaki użytkownik jest obecnie zalogowany). Zamiast frazy "CollectorComputerName" użytkownik powinien podstawić nazwę maszyny, na której działa Zdalny Kolektor. Nowy certyfikat pojawi się w folderze z Osobistymi Certyfikatami dla komputera lokalnego w konsoli MMC (jest to narzędzie systemu Windows). |
Bezpieczna komunikacja SCADA po HTTPS - utworzenie samodzielnie podpisanego certyfikatu |
Instalacja certyfikatu X.509 w wymaganych lokalizacjach
Powyższe czynności nie kończą pracy nad nowo utworzonym certyfikatem. Kolejny etap do edycja użytkowników do niego przyporządkowanych oraz określenie ich praw.
W tym celu należy wybrać PPM omawiany certyfikat, znajdujący się w katalogu "Osobisty" dla lokalnego komputera w konsoli MMC. Przechodząc następnie do opcji: Wszystkie Zadania->Zarządzaj Kluczami Prywatnymi otwiera się okno konfiguracyjne. Za jego pomocą można dokonać odpowiednich ustawień - dodać użytkownika, "pod którym" działa usługa Zdalnego Kolektora (np. ICONICS_USER) oraz nadać mu co najmniej uprawnienia odczytu.
|
Następnie należy wyeksportować ten certyfikat (PPM->Wszystkie Zadania ->Exportuj) bez klucza prywatnego. Teraz musi nastąpić jego ponowny import do katalogu "Zaufane główne urzędy certyfikacji" w konsoli MMC, aby ten certyfikat stał się zaufanym w obrębie tej maszyny.
|
Instalacja certyfikatu X.509 w wymaganych lokalizacjach |
Przypisanie certyfikatu do portu komunikacyjnego i konfiguracja FrameWorX
Jak powiedziano na początku, protokół HTTPS działa domyślnie na porcie 443. Dlatego, że dysponuje się tutaj instalacją jedynie samego kolektora, nie ma możliwości przeprowadzenia odpowiedniego przypisania za pomocą programu IIS. Trzeba to więc wykonać z poziomu Wiersza Polecenia.
W tym celu należy wpisać następującą komendę.
netsh http add sslcert ipport=0.0.0.0:443 appid={4dc3e181-e14b-4a21-b02259fc669b0914} certhash=...
Przy czym w miejsce "..." należy wstawić ciąg znaków będący "odciskiem palca" (ang. Thumbprint) nowo utworzonego certyfikatu. Parametr ten można uzyskać poprzez wybór (2 x LMP) ikonki wyeksportowanego certyfikatu na pulpicie i przejście do zakładki "Szczegóły".
Najlepszą praktyką jest ręczne przepisanie tego kodu, w celu uniknięcia kopiowania ukrytych znaków.
W celu sprawdzenia poprawności przypisania, można użyć poniższej komendy.
netsh http show sslcert
Ostatnim już krokiem na maszynie z Kolektorem jest przejście do lokalizacji: C:\ProgramData\ICONICS (za pomocą eksploratora plików) i edycja pliku Client.local.xml. Zmiany należy wprowadzić w dwóch miejscach, według poniższego przykładu.
|
Przypisanie certyfikatu do portu oraz konfiguracja FrameWorX |
Konfigurację maszyny kończy restart usług: ICONICS FrameWorX oraz ICONICS Hyper Historian Collector lub ponowne uruchomienie komputera.
Aby umożliwić komunikację po HTTPS należy upewnić się, że Firewall nie blokuje połączeń wejściowych na porcie 443.
Konfiguracja Loggera do bezpiecznej komunikacji po HTTPS
Działania podejmowane na maszynie z Logger'em będą krótsze niż w przypadku tej z kolektorem.
Pierwszym z nich jest skopiowanie utworzonego wcześniej certyfikatu (bez klucza publicznego) na komputer z Logger'em. Następnie należy go zaimportować w konsoli MMC do katalogu "Zaufane Osoby" dla komputera lokalnego. Od tego momentu maszyna z Logger'em będzie "ufać" komputerowi z działającym Zdalnym Kolektorem.
Konfigurację kończy odpowiednia modyfikacja ustawień Zdalnego Kolektora w środowisku Workbench. Względem ustawień poczynionych w artykule (do którego link dołączono na początku tego wpisu) trzeba zmienić jedynie protokół komunikacyjny (na Https Over FrameWorX) oraz upewnić się, że wygenerowany adres URL kolektora jest poniższej postaci.
https://<nazwa_maszyny_z_kolektorem>:443/BasicHttps
Teraz musi nastąpić ponowne uruchomienie usług: ICONICS FrameWorX oraz ICONICS Hyper Historian Logger (np. z poziomu okna "Usługi" w Windows).
Prezentacja rezultatów
|
Na koniec wpisu, którego przedmiotem była konfiguracja Zdalnego Kolektora, dodano dwie zmienne pochodzące z serwera OPC działającego na maszynie z kolektorem. Są one archiwizowane przez Logger na maszynie z całym pakietem GENESIS64. Poniższy krótki film przedstawi działanie komunikacji z wykorzystaniem certyfikatów.
|
Prezentacja bezpiecznej archiwizacji w systemie SCADA |
Podsumowanie
W związku z wprowadzaniem rozwiązań z zakresu Przemysłu 4.0 lub Internet of Things, bezpieczna komunikacja w systemach SCADA (np. z wykorzystaniem HTTPS) jest narzędziem niezbędnym do niezakłóconego działania przedsiębiorstwa. W momencie, gdy archiwizowane dane procesowe muszą zostać przetransportowane przez sieć, lub wyprowadzone do chmury, trzeba wziąć pod uwagę ryzyko ich przechwycenia przez osoby trzecie.
ICONICS wyposażył swoje produkty w możliwość integracji z uniwersalnymi formami zabezpieczeń (jak np. certyfikaty X.509), co powoduje, że wymiana danych spełnia wszystkie wymogi bezpieczeństwa.
Import danych offline do systemu SCADA
Słowem wstępu
W praktyce często zdarza się, że połączenie na linii: urządzenie generujące dane - moduł archiwizacji zostaje przerwane. Zdarza się również, że zachodzi potrzeba wprowadzenia do nowego systemu danych z urządzeń, gromadzonych przez dłuższy okres czasu wstecz.
W obydwu przypadkach, interesujące nas informacje gromadzi się w zastępczych lokalizacjach w formie plików o różnym formacie. Wpis ten powstał w celu zaprezentowania dwóch możliwych rozwiązań pozwalających na import takich danych do modułu Hyper Historian.
Moduł archiwizacji Hyper Historian od ICONICS to rozbudowane narzędzie. Oferuje ono zarówno funkcjonalności takie jak wydajność (zapis do 100 000 wartości zmiennych na sekundę), jak i niezawodność (możliwość konfiguracji redundancji). Z uwagi na szeroki wachlarz możliwości, Hyper Historian to rekomendowany przez ICONICS produkt do obsługi archiwizacji danych procesowych, w zastępstwie standardowych baz danych (np. SQL). Z tego powodu warto zapoznać się z mechanizmami wprowadzania dowolnych danych do tego modułu.
W dalszej części wpisu zaprezentowano dwa sposoby importu danych do Hyper Historian:
- z plików .csv - za pomocą natywnego narzędzia MergeWorX,
- z dowolnego źródła obsługiwanego przez GENESIS64 - przy użyciu silnika SQL Hyper Historian.
Import danych z plików .csv
Działanie narzędzia - MergeWorX
Pakiet GENESIS64 jest wyposażony w natywne narzędzie służące do importu danych do modułu Hyper Historian - MergeWorX. Pozwala ono na dodawanie nowych źródeł danych (Plugins), z których dane zostają importowane w określony sposób.
Aby skonfigurować dany Plugin, należy wypełnić kilka opcji. Są to m.in:
- Plugin Type - typ źródła danych: CSV lub MELIPC Output CSV;
- Output Node Prefix - ścieżka do serwera z docelowym Hyper Historian; jeśli znajduje się on na maszynie lokalnej, należy pozostawić puste;
- Trigger Point - wybrany trigger, który wyzwala działanie danego plugin'u.
|
Dalej użytkownik określa informacje na temat plików z danymi. Określa on między innymi:
Dodatkowo, operator określa lokalizację dla archiwizowanych plików (jeśli taka następuje) oraz miejsce, do którego MergeWorX przenosi je po nieudanym imporcie. |
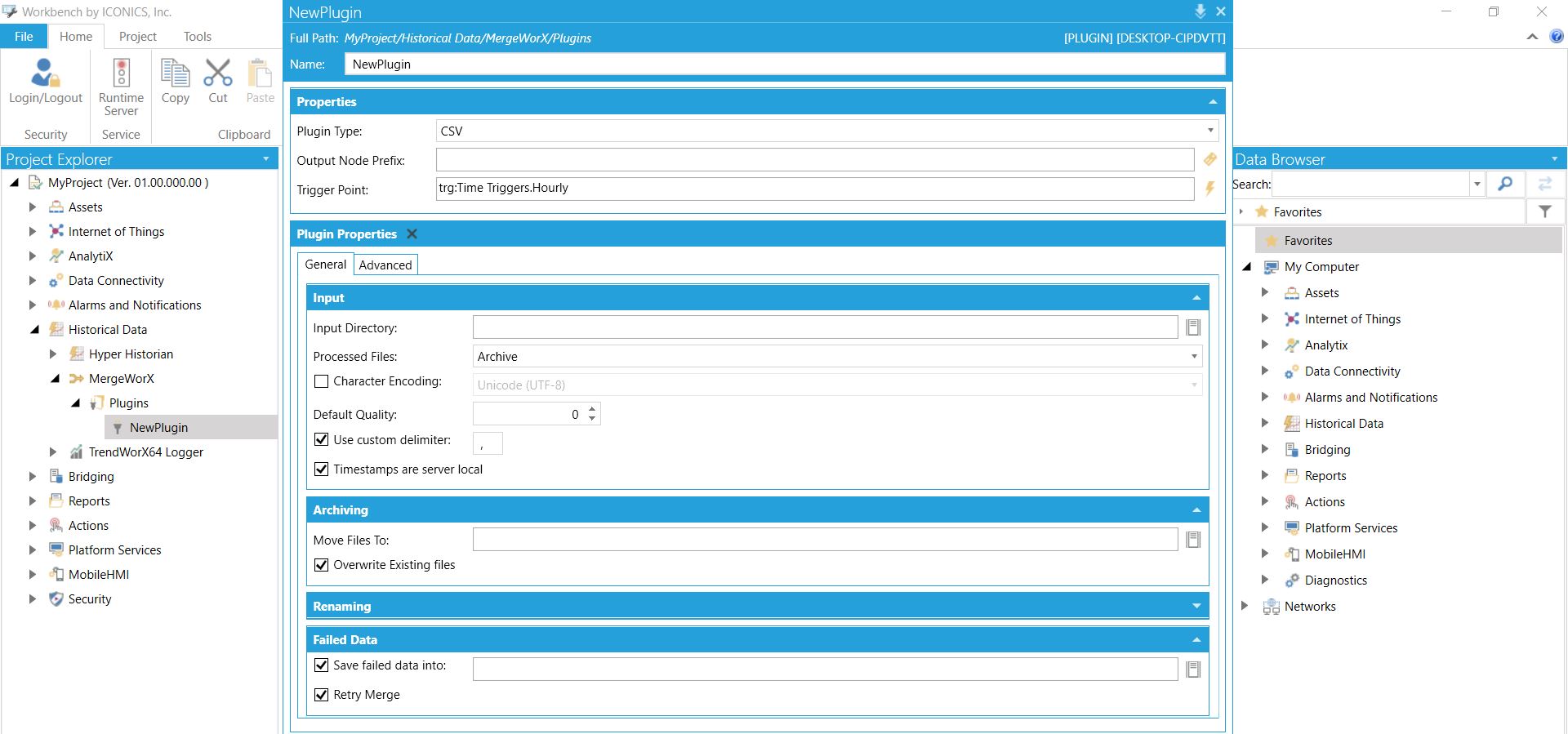 Ustawienia modułu pozwalającego na import danych offline - MergeWorX Ustawienia modułu pozwalającego na import danych offline - MergeWorX |
Wymagana struktura plików .csv
W plikach csv można zawrzeć kilka informacji dotyczących archiwizowanych zmiennych. Są to na przykład:
|
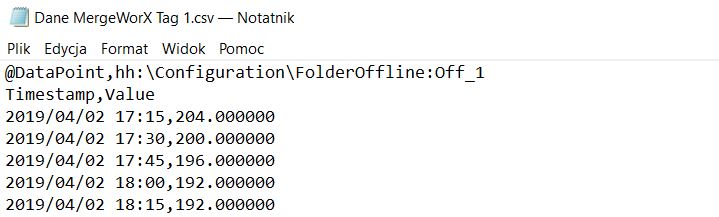 Struktura pliku csv z danymi offline do importu w systemie SCADA Struktura pliku csv z danymi offline do importu w systemie SCADA |
|
Pliki powinny wyglądać tak, aby dla każdej zmiennej najpierw podać kolejność wprowadzanych parametrów - poprzez wypisanie kolejno powyższych słów kluczowych, a następnie zawarcie w kolejnych linijkach całego zbioru parametrów dla danej zmiennej. Przykład znajduje się poniżej. Wczytanie pliku o takiej zawartości spowoduje wprowadzenie danych do tagu o nazwie Off_1 znajdującego się w folderze FolderOffline pod konfiguracją lokalnego HyperHistorian. Wprowadzane informacje dotyczą stempla czasowego i wartości - jest to niezbędne minimum. |
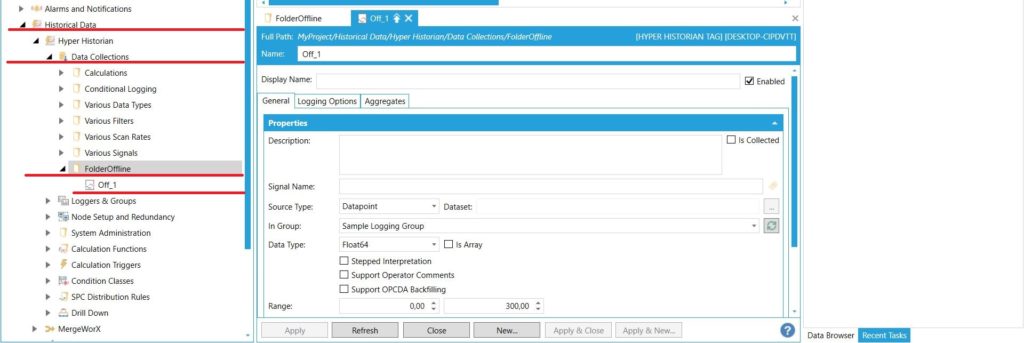 Lokalizacja zmiennej w Hyper Historian Lokalizacja zmiennej w Hyper Historian |
|
Co więcej, w jednym pliku csv mogą być zawarte dane odnośnie więcej niż jednej zmiennej. Pierwszy sposób polega na powtórzeniu nagłówka z powyższego zdjęcia po ostatniej linijce pliku (ze zmienioną ścieżką do docelowej zmiennej) oraz dopisaniu nowych rekordów. Druga opcja natomiast zakłada dodawanie informacji o zmiennych w plikach na przemian - po jednym rekordzie danych dla danego tagu na raz. W tym przypadku plik csv wyglądałby w następujący sposób. |
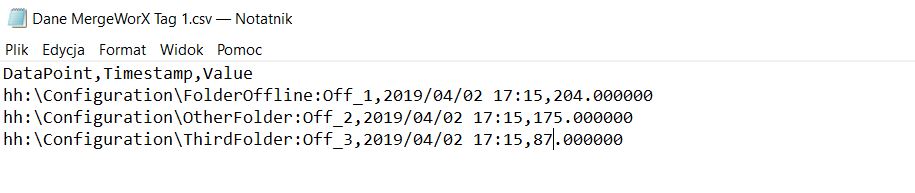 Alternatywna struktura pliku csv Alternatywna struktura pliku csv |
Poniższy film pokazuje zarówno przykładową procedurę importu wartości dwóch zmiennych (pierwsza część), jak i metody ich wizualizacji na wykresach (druga część).
Import danych za pomocą HH SQL Query Engine
W tej sekcji przedstawiono przykład projektu zapewniającego zautomatyzowany import danych do systemu SCADA. Kluczowym punktem jest tu wykorzystanie silnika zapytań SQL, w jaki wyposażony jest Hyper Historian, jak również obecności tego modułu na liście serwerów dołączonych w SQL Management Studio. Dzięki powyższym dwóm faktom można stworzyć procedurę, która spowoduje wykonanie na serwerze dołączonym funkcji "INSERT". Procedura zawierać będzie parametry dzięki czemu można ją wykorzystać do różnych zestawów danych.
Taką procedurę można wywołać na przykład za pomocą narzędzia GridWorX w systemie GENESIS64. Całkowite zautomatyzowanie procesu uzyskuje się dodatkowo dzięki wdrożeniu narzędzi BridgeWorX oraz trigger'ów. Pierwsze z nich odpowiada za wykonanie algorytmu importu danych, a drugie wywołuje pracę BridgeWorX po wykryciu nowego zestawu danych.
Procedura SQL do importu danych w systemie SCADA
Serwerem bazy danych wykorzystywanych w tym przypadku jest MS SQL Server 2014 Express. Oczywiście możliwych kodów procedur SQL, które realizuję wyżej postawione zadanie, jest dużo. Jeden z przykładowych można podejrzeć niżej.
Pobiera ona parametry takie, jak:
|
Procedura importu danych w SQL Management Studio |
|
Powyższą procedurę należy zainstalować np. pod konfiguracyjną bazą danych Hyper Historian w SQL Management Studio (razem z domyślnymi procedurami od ICONICS). Kolejny krok to skonfigurowanie narzędzie GridWorX w pakiecie GENSIS64 w celu wykonywania powyższej procedury SQL. |
Konfiguracja Hyper Historian
Pierwszą rzeczą, jaką należy wykonać, jest dostosowanie ustawień Loggera Hyper Historian, pokazanego na zdjęciu niżej. Odpowiada on za zapis danych do plików na dysku komputera.
| Wszystkie ustawienia użytkownik może dostosować według własnych preferencji - zgodnie z instrukcjami lub plikami pomocy. Uwagę należy jednak zwrócić na opcję "Starting At". Jest to początkowa data dla archiwizowanych wartości. Logger nie zapisze żadnych pomiarów posiadających stempel czasowy wcześniejszy od podanego w tym miejscu. Nie ważne, czy archiwizacja będzie wymuszana za pomocą MergeWorX, SQL Query Engine, czy w standardowy sposób. | 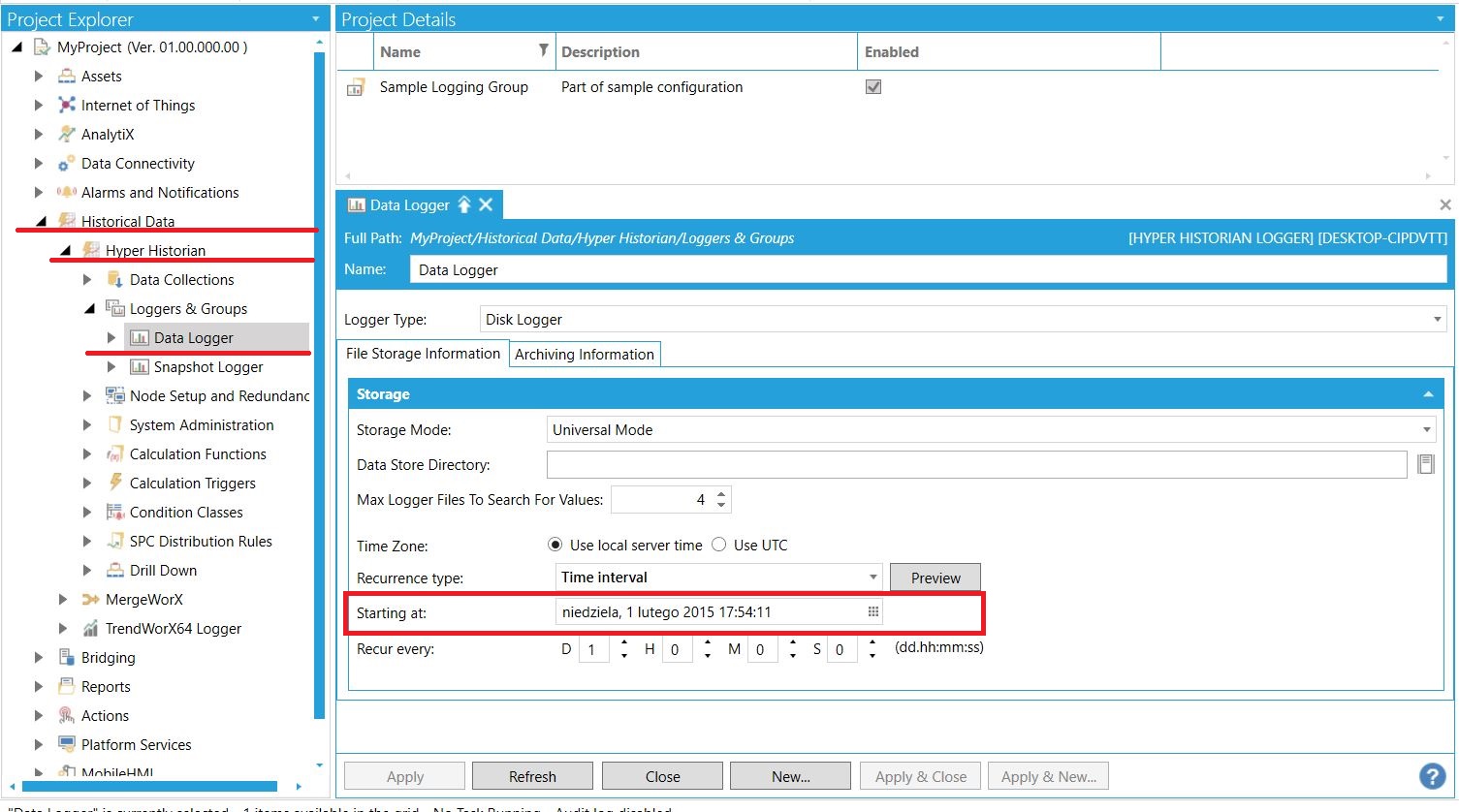 |
|
Następny etap to dodanie archiwizowanego tagu pod konfiguracją Hyper Historian. Jego nazwa oraz folder, w jakim będzie się znajdował, determinują wartości parametrów przekazywanych do Data Manipulator'a w GridWorX. Przykład takiego tagu znajduje się na zdjęciu poniżej. W tym przypadku odznaczono opcję "Is Collected", dzięki czemu nie trzeba podawać tu ścieżki do archiwizowanej zmiennej (wszystkie dane pod tym tagiem pochodzą z ręcznego procesu ich wprowadzania). Możliwe jest jednak również edytowanie, wstawianie i usuwanie wartości zmiennych archiwizowanych automatycznie. |
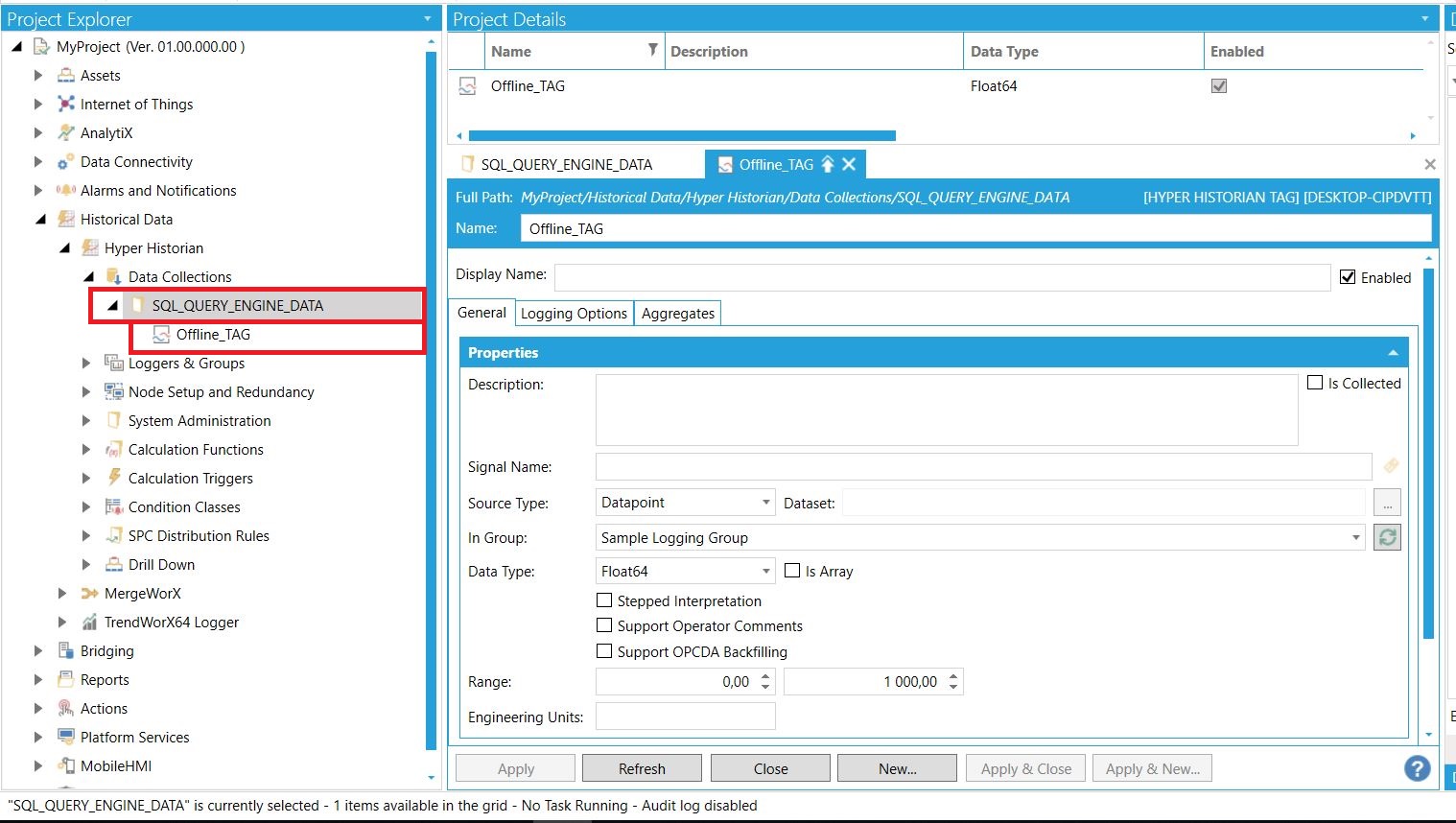 Konfiguracja archiwizowanej zmiennej offline w module Hyper Historian Konfiguracja archiwizowanej zmiennej offline w module Hyper Historian |
Wprowadzanie danych offline
|
W najprostszym przypadku można odnaleźć parametry należące do utworzonego wcześniej Data Manipulatora (za pomocą Data Explorer), wyedytować je, a następnie wywołać działanie procedury za pomocą zmiennej @@Execute. Ścieżka dostępu do tych parametrów w oknie Data Explorer jej taka sam jak na zdjęciu obok. Wyszukiwarka danych w programie Data Explorer jest taka sama jak w oknie GENESIS. |
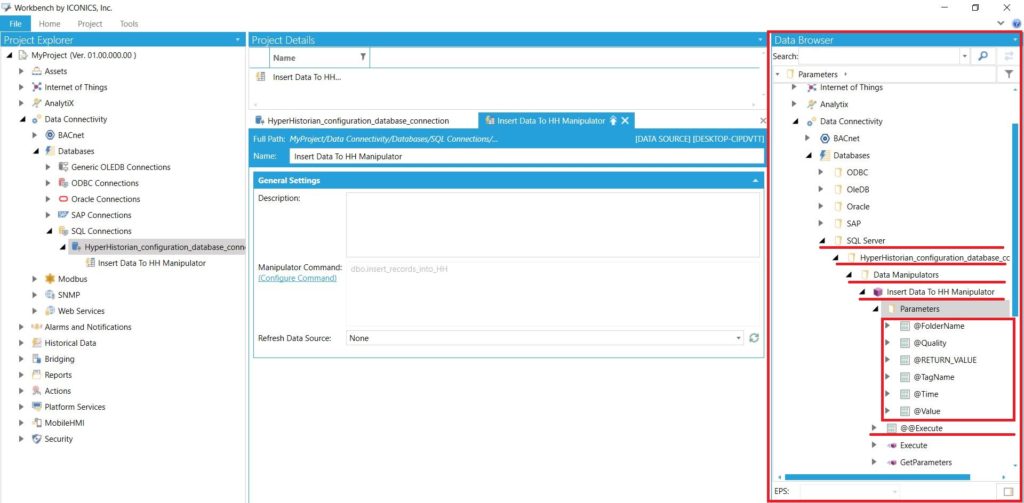 Parametry utworzonego Data Manipulator'a widoczne w Data Browser Parametry utworzonego Data Manipulator'a widoczne w Data Browser |
Za pomocą Data Explorer można również śledzić to, jak przebiega import danych do zmiennej offline w systemie SCADA. Wystarczy wyszukać ją w drzewku po lewej stronie (patrz film poniżej) i przełączyć odczyt na tryb wykresu.
Automatyzacja procesu
Na powyższym filmie import danych offline do systemu SCADA realizowany jest ręcznie. Jest to dobry sposób tylko w przypadku, gdy istnieje potrzeba dodania lub edycji pojedynczych próbek danych.
Jeśli chodzi o zautomatyzowanie procesu importu danych, można posłużyć się narzędziami takimi jak BridgeWorX - służącym do graficznego tworzenia algorytmów wykonywanych w obrębie systemu SCADA. W ramach tego modułu użytkownik posiada szeroki wybór bloków funkcyjnych, z których można układać schematy przepływu danych (ang. Workflows). Co więcej, algorytmy BridgeWorX wykonywane są w systemie przy wystąpieniu określonych warunków - np. przy ich ręcznym uruchomieniu przez operatora, lub pobudzeniu przy pomocy dowolnego trigger'a.
Automatyczny eksport danych archiwalnych
Jak w prosty sposób skonfigurować automatyczny eksport danych archiwalnych z systemu SCADA ICONICS w celu integracji z zewnętrznym oprogramowaniem?
Nowe narzędzie - Data Exporter
Po wydaniu nowej wersji oprogramowania SCADA ICONICS (wersja 10.96), moduł archiwizacji Hyper Historian uzyskał dodatkowe funkcje. Jedną z nich jest narzędzie Data Exporter służące w celu prowadzenia prostego i automatycznego eksportu danych archiwalnych z tego modułu.
Eksport danych może następować na kilka sposobów. Zewnętrzne kompatybilne narzędzia oraz formaty plików wymieniono niżej.
- Microsoft SQL Server (w tym Express),
- Microsoft Azure SQL,
- Lokalne pliki z rozszerzeniem .CSV,
- Microsoft Azure Data Lake,
- Apache Kafka,
- Apache Hadoop.
W przypadku naszego wpisu, zaprezentujemy krótki tutorial pokazujący współpracę Hyper Historian z lokalnie działającym serwerem SQL.
Należy pamiętać, że Hyper Historian jest dostępny w 3 wersjach, które różnią się zakresem funkcjonalności. Narzędzie Data Exporter wpierają wersje Standard oraz Enterprise tego modułu archiwizacji.
Eksport danych archiwalnych - praca z Data Exporter
Instalacja Data Exporter w bazie danych Hyper Historian
|
Aby móc korzystać z automatycznego przekazywania danych do zewnętrznych programów, należy najpierw zainstalować narzędzie Data Exporter w bazie HyperHistorian. Ważne jest, aby wybrać aktywną bazę konfiguracyjną Hyper Historian. W tym celu, w oknie programu Workbench, przechodzimy do lokalizacji pokazanej niżej i wybieramy opcję Configure Database. |
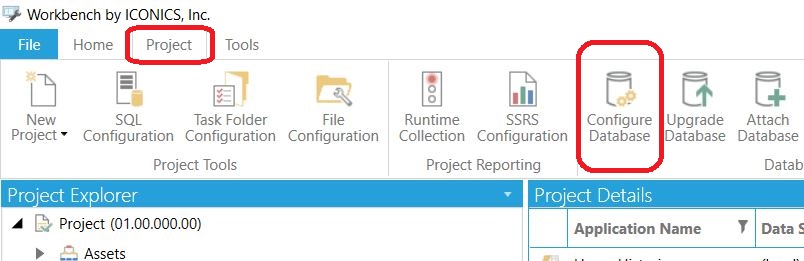 Workbench - Konfiguracja Bazy danych Hyper Historian Workbench - Konfiguracja Bazy danych Hyper Historian |
|
W nowo otworzonym oknie wskazujemy, którą bazę chcemy konfigurować (ma być to aktywna baza danych używana przez Hyper Historian). W kolejnym oknie zaznaczamy, że chcemy zainstalować w tej bazie dodatek Data Exporter. |
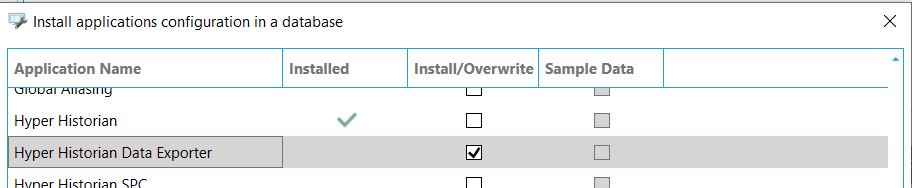 Konfiguracja bazy danych Hyper Historian - instalacja Data Exporter Konfiguracja bazy danych Hyper Historian - instalacja Data Exporter |
|
Klikamy "Install" - i już. Przechodzimy do lokalizacji pokazanej na poniższym zdjęciu w celu upewnienia się, że Data Exporter jest oznaczony jako aktywny (Enabled).
|
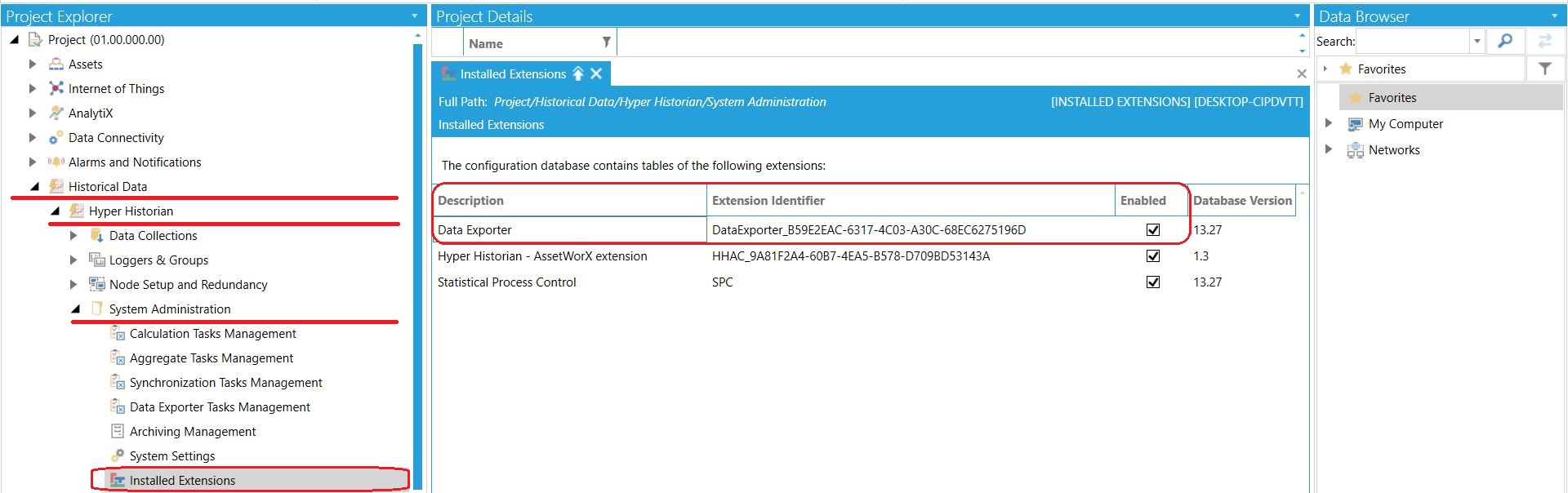 Eksport danych - odblokowanie narzędzia DataExporter Eksport danych - odblokowanie narzędzia DataExporter |
Określenie zbioru eksportowanych zmiennych
|
Pierwszy krok to rozwinięcie gałęzi Data Exporters pod konfiguracją HyperHistorian w Workbench, w celu ustalenia jakie dane będą przesyłane. W folderze Datasets dodajemy nowy zestaw danych.
Możliwe jest zarówno eksportowanie "surowych" informacji (raw), jak i zdefiniowanie wstępnych obliczeń (aggregates).
|
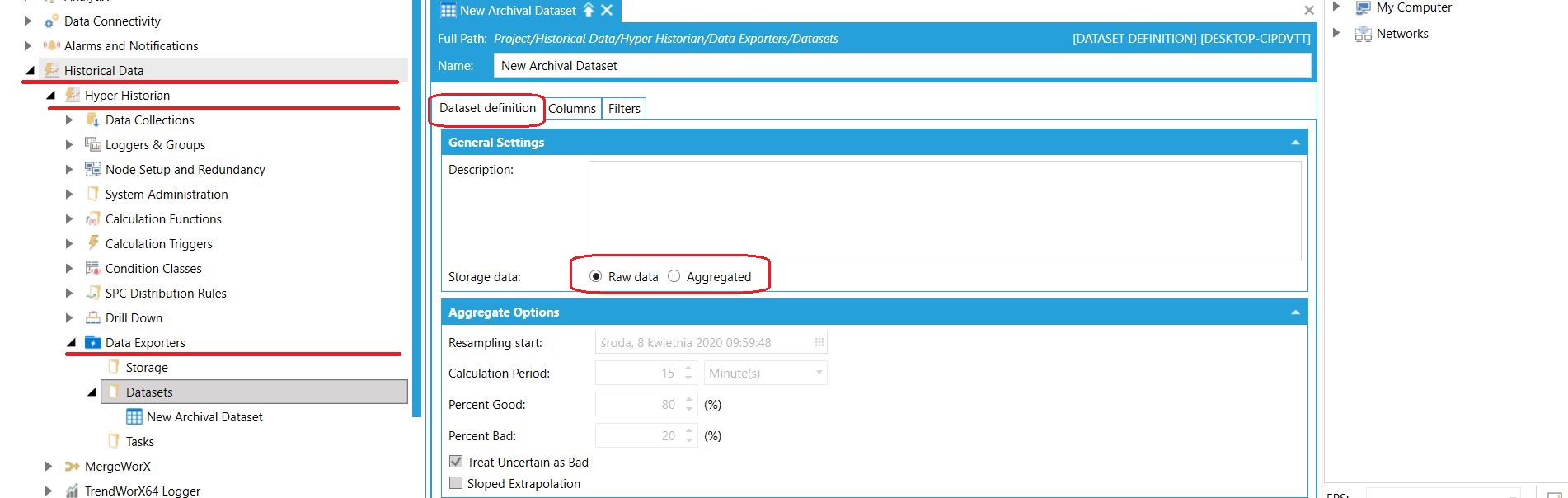 Definicja zestawu danych do eksportu Definicja zestawu danych do eksportu |
W tym przypadku wyeksportujemy surowe dane. W kolejnej zakładce definiujemy natomiast, jakie elementy zawierać będzie pojedynczy rekord danych. Domyślnie są to: Point Name (nazwa zmiennej), Status (jakość próbki), Timestamp (data/czas) oraz Value.
|
Możesz dodać inne kolumny - spośród zdefiniowanych fabrycznie w systemie lub, co więcej, dodać własną kolumnę zawierającą wartość obliczaną według Twojego wzoru. Na przykład, niżej dodaliśmy kolumnę, która zawiera informację o jednostkach, w jakich prowadzone były pomiary. Jest to wbudowany typ kolumny. Informacje o jednostkach wprowadza się natomiast przy dodawaniu określonej zmiennej archiwalnej w Hyper Historian.
|
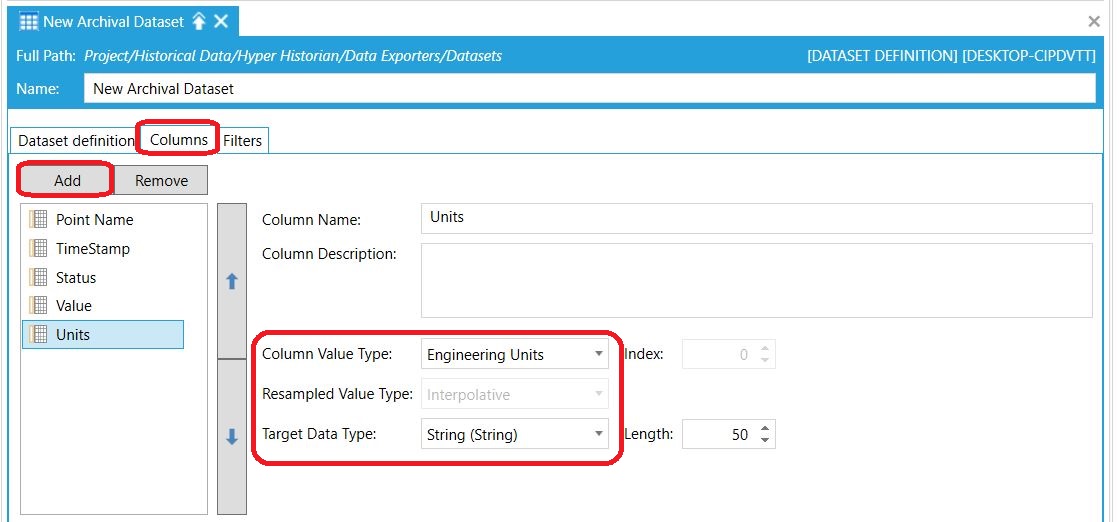 Definicja kolumn w pojedynczym rekordzie Definicja kolumn w pojedynczym rekordzie |
|
Na koniec musimy natomiast określić, wartości których archiwizowanych zmiennych mają być wyeksportowane na nasz serwer SQL. Służy do tego ostatnia zakładka - "Filters". W tym przypadku wskażemy dwie wcześniej przygotowane zmienne. Istnieje możliwość stosowania różnych filtrów dla eksportowanych danych. Co więcej, filtry te można parametryzować. Dzięki temu, raz zdefiniowany zestaw danych można wykorzystać wielokrotnie, w wielu aplikacjach. Aby uzyskać więcej informacji, skontaktuj się z nami pod adresem e-mail podanym na końcu wpisu.
|
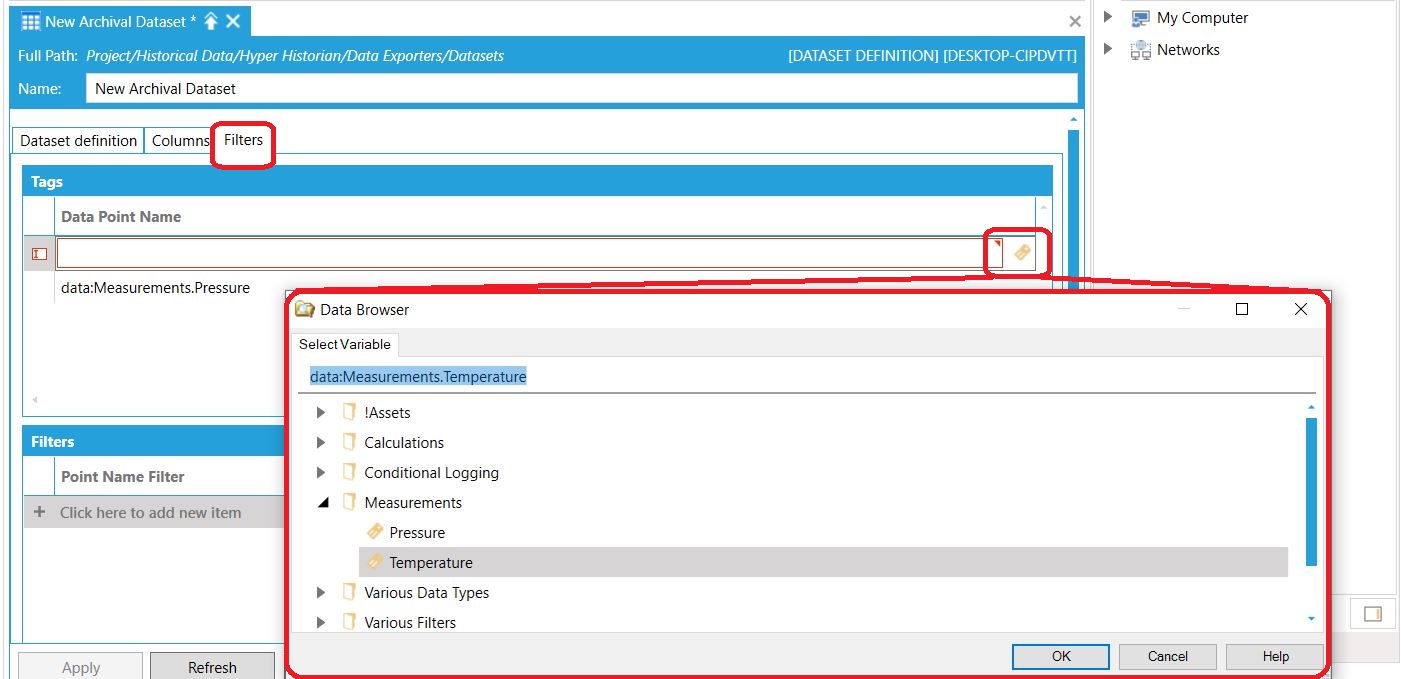 Dodanie listy eksportowanych zmiennych Dodanie listy eksportowanych zmiennych |
Wskazanie miejsca eksportu
Teraz, przechodzimy do folderu Storage pod konfiguracją Data Exporters, w celu zdefiniowania, dokąd mają trafić dane. Dodajemy nowy obiekt "Data Storage" w tym folderze.
|
Nadajemy mu nazwę oraz z pośród wielu opcji eksportu (wymienionych na początku wpisu) wybieramy SQL/Azure SQL. Za pomocą opcji Configure Connection ustanawiamy połączenie z bazą danych - poprzez wskazanie serwera SQL oraz podanie poświadczeń. Baza danych może być pusta - Data Exporter utworzy wtedy samodzielnie potrzebne tabele. |
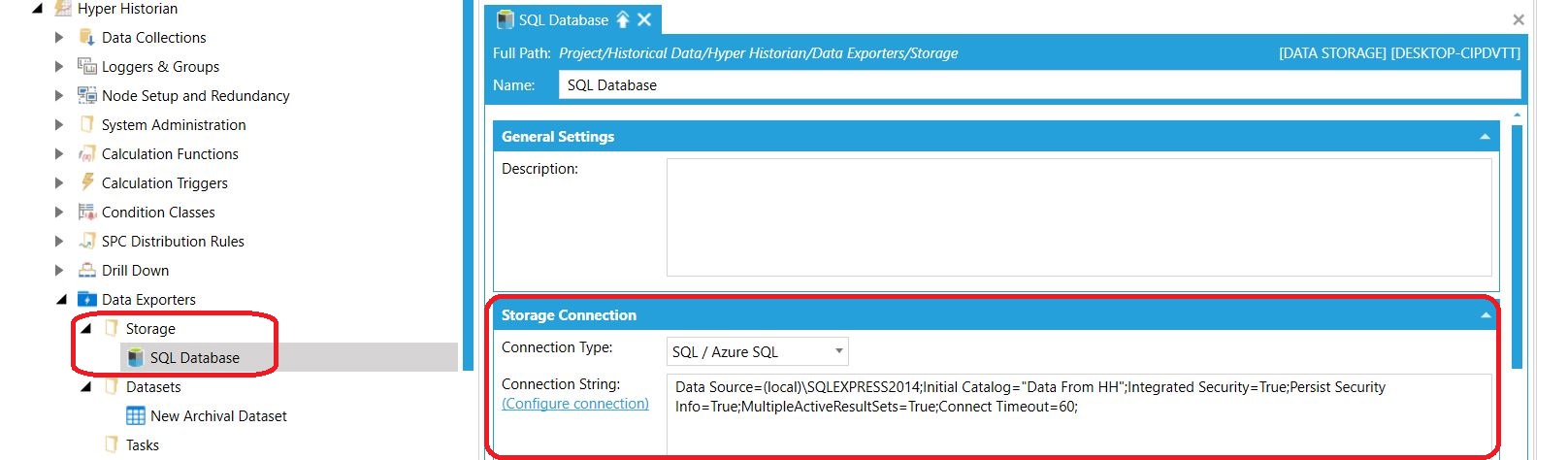 Wskazanie lokalizacji do eksportu danych - bazy danych na serwerze SQL Wskazanie lokalizacji do eksportu danych - bazy danych na serwerze SQL |
Automatyzacja eksportu danych
|
Automatyczny eksport ustawia się poprzez dodanie nowego obiektu Synchronization Task do folderu Tasks. Ustalamy jego nazwę, zaznaczamy, że jest on aktywny oraz, co ważne - wybieramy lokalizację do eksportu (nasz Data Storage) i ustawiamy odpowiedni trigger, który zautomatyzuje nam cały proces. W naszym przypadku wybraliśmy wcześniej dodany trigger, który wyzwala się co 5 minut. W systemie SCADA ICONICS istnieje wiele rodzajów trigger'ów. |
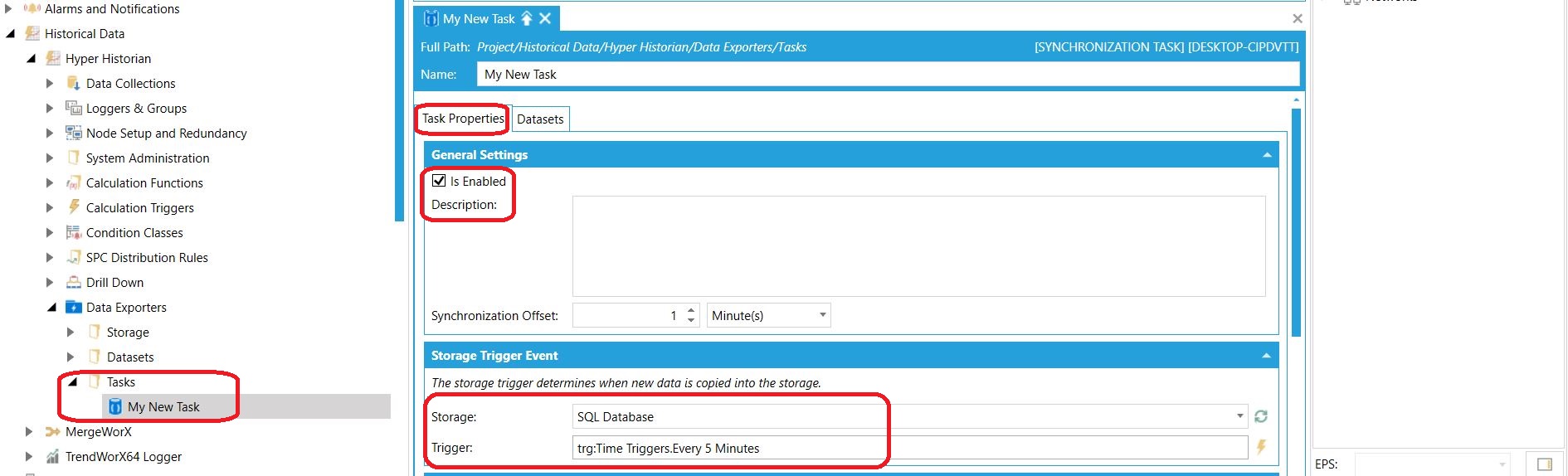 Definicja nowego zadania eksportu Definicja nowego zadania eksportu |
|
Dodatkowo, istnieje możliwość zarządzania strukturą przechowywanych danych w naszej docelowej lokalizacji. Na przykład, wprowadzając ustawienia jak niżej (w sekcji Data Storage Schedule, w tej samej lokalizacji), możemy spowodować, że system utworzy nową tabelę dla danych w bazie SQL co 10 minut. Możemy również wyłączyć tę opcję i przechowywać wszystkie dane w jednej tabeli.
|
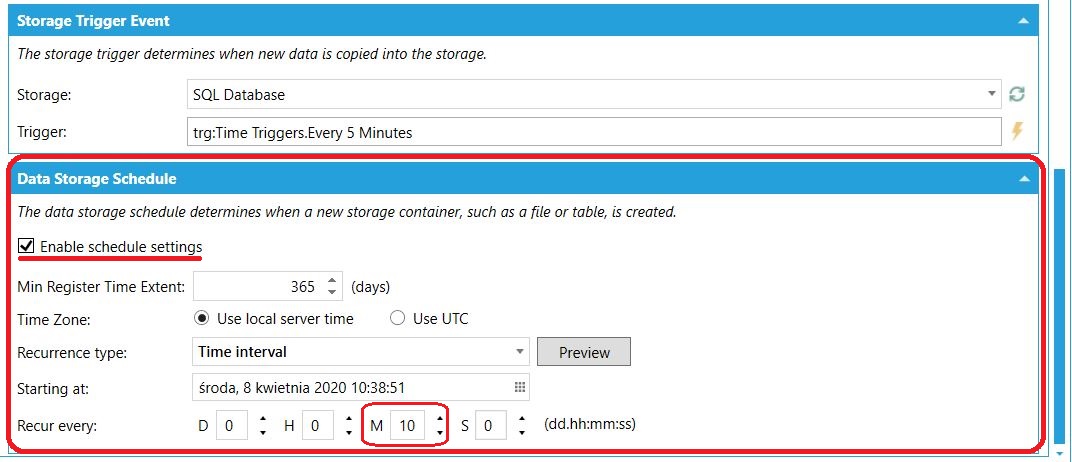 Zarządzanie strukturą danych w docelowej lokalizacji Zarządzanie strukturą danych w docelowej lokalizacji |
|
Ostatni już krok polega na przejściu do zakładki Datasets w celu określenia, które zestawy danych podlegają pod to konkretne zadanie eksportu. My wybieramy oczywiście nasz zestaw utworzony wyżej. Dodatkowo, jeśli podczas definiowania zestawów danych użyliśmy parametrów (aliasów), możemy określić ich wartości w sekcji Aliases widocznej na powyższym zdjęciu. Aby dowiedzieć się więcej, skontaktuj się z nami pod adresem e-mail podanym na końcu wpisu.
|
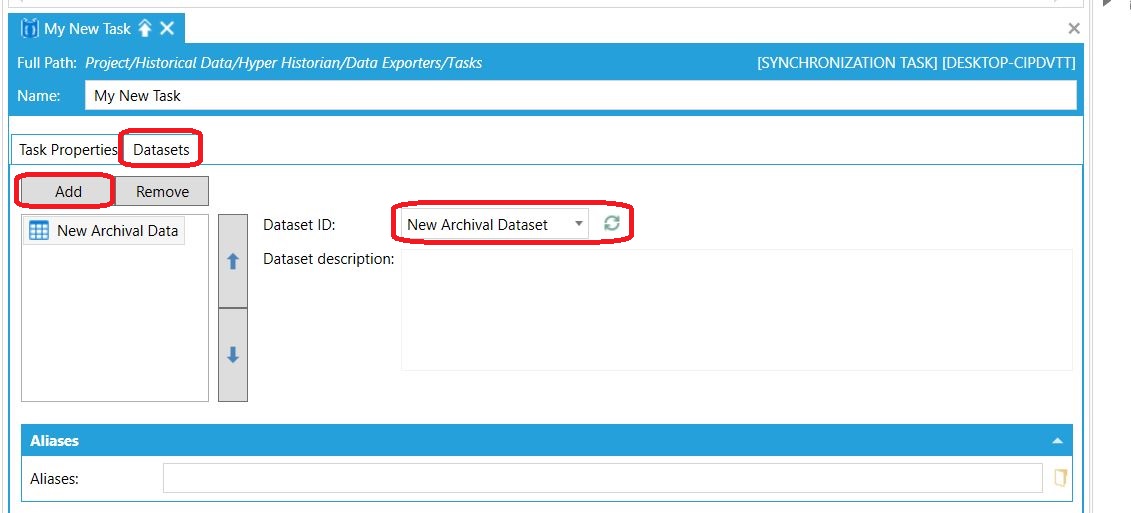 Określenie zestawów danych do eksportu z systemu SCADA Określenie zestawów danych do eksportu z systemu SCADA |
Podsumowanie
W tym miejscu kończy się ten krótki poradnik utworzony w celu objaśnienia podstaw obsługi narzędzia Data Exporter. Teraz, po uruchomieniu usługi Hyper Historian, możemy odczekać odpowiednią ilość czasu (u nas: 5 minut) i zaobserwować efekty eksportu w bazie SQL.
| Oczywiście, dowiedziałeś się tutaj zupełnych podstaw na temat nowej funkcjonalności Hyper Historian w systemie SCADA ICONICS. Nie wspomnieliśmy natomiast o bardziej zaawansowanych aspektach, jak na przykład używanie filtrów dla zestawów danych (wraz z parametrami). Dzięki nim możesz utworzyć jedną definicję zakresu danych do eksportu i dostosowywać ją na bieżąco dla konkretnego zadania - określając tylko wartości użytych parametrów. | 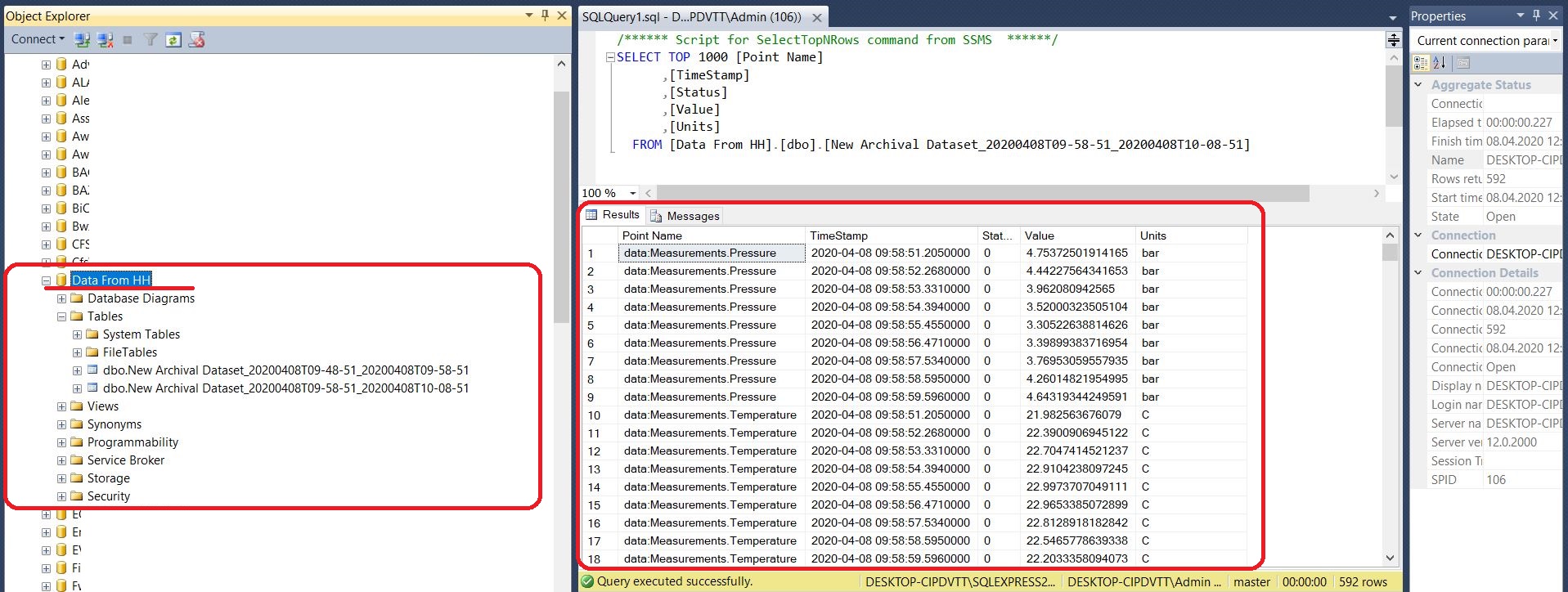 Dane z Hyper Historian w SQL Dane z Hyper Historian w SQL |





















