Ekspert poleca




Rozwój przemysłu wymaga narzędzi, które będą elastyczne, skalowalne i gotowe na wyzwania związane z cyfryzacją produkcji. HMINavi jest przykładem platformy HMI, która odpowiada na te potrzeby, łącząc intuicyjne środowisko projektowe z zaawansowanymi funkcjami komunikacyjnymi, analizą danych historycznych, obsługą MQTT oraz rozbudowanym systemem alarmowym.

Payload, promienie mieszania, prędkości, przyspieszenia i ustawienia ruchu w PolyScope. Czytaj całość!

Cyfryzacja procesów produkcyjnych oraz rozwój Przemysłowego Internetu Rzeczy (IIoT) sprawiają, że przedsiębiorstwa coraz częściej wdrażają rozwiązania umożliwiające zdalne monitorowanie maszyn, analizę danych oraz automatyczne sterowanie procesami. Jednym z elementów takiej infrastruktury są przemysłowe moduły Wi-Fi I/O, które pozwalają na bezprzewodową komunikację pomiędzy urządzeniami, sterownikami PLC, systemami SCADA oraz platformami chmurowymi.
-
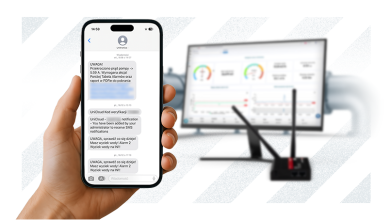
UniCloud umożliwia monitoring obiektów wod-kan bez własnych serwerów, drogich licencji i kosztownego utrzymania systemu SCADA.
-
Dobór dysku SSD i pamięci RAM do zabudowy przemysłowej rzadko sprowadza się do samej pojemności — liczą się zakres temperatur pracy, interfejs, format i typ pamięci. Udostępniamy pełną, aktualną listę dysków SSD (25 SKU, 128 GB – 4 TB, SATA III i PCIe NVMe) oraz modułów RAM (23 SKU, DDR3L / DDR4 / DDR5, DIMM i SODIMM) dostępnych od ręki z magazynu w Warszawie. Dwie interaktywne wyszukiwarki pozwalają filtrować asortyment po kluczowych parametrach i szybko zawęzić listę do komponentów pasujących do Twojej platformy.
-
Kontroluj rozproszone obiekty bez ruszania się z biura!
-
Poznaj certyfikowane i zgodne z IEC 62443-4-2 urządzenia Moxa dla cyberbezpieczeństwa OT: routery, switche, serwery portów szeregowych, komputery przemysłowe i bramy komunikacyjne.
-
Rozwiązanie problemu, gdy system Polyscope nie uruchamia się poprawnie
-
Czas złożyć wszystko w jedną decyzję. W ostatniej części prowadzimy Cię ścieżką doboru stacji pod lokalne AI: od wzoru na rozmiar, przez gotowe scenariusze sprzętowe, po pełny stos. Pokazujemy też, dlaczego chmura ma swoje problemy, czyli nieprzewidywalne ceny, zależność od dostawcy i prywatność danych, i kiedy rachunek wychodzi po stronie rozwiązania lokalnego.
-
Każdy wat, który wchodzi do GPU, wychodzi jako ciepło, a to ciepło wyznacza realne granice projektu. W tej części omawiamy pobór mocy nowoczesnych akceleratorów, gęstość mocy w szafie rack i progi przejścia z chłodzenia powietrznego na ciecz oraz immersję, a także dobór form factoru: od bezwentylatorowego BoxPC na brzegu sieci po serwer w racku.